
:quality(80)/p7i.vogel.de/wcms/1f/a8/1fa8fd131fcfb660575dc576e9452be6/0132195461v1.jpeg "Laut Schneider Electrics ist die Chiller-Baureihe für Rechenzentrumsbetreiber, die auf Liquid Cooling für KI- und Hochleistungsrechnen (HPC) umstellen oder bereits umgestellt haben, gedacht. (Bild: Midjourney / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/25/ba/25ba46cb0d57f75776466da277dac3ff/0132182757v1.jpeg "Mit steigender GPU-Dichte wachsen auch die Anforderungen an die Leistungsfähigkeit und Skalierbarkeit der Storage-Infrastruktur. (Bild: © Gorodenkoff - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/24/76/247663fa1c5b8dd132e30cd93d298254/0132140525v1.jpeg "An stromhungrige Datacenter vermaktet Rolls-Royce Gas, Nuklear, Diesel, Batterien und Erneurbare zugleich. Ist das noch Energiewende? Ja, argumentiert Michael Stipa. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/9b/74/9b7400774dbb0f4203d632733dd22aed/0132154902v1.jpeg "Wenn sich die Politik nicht schneller bewegt, bleibt Europas Vision eines verteilten Netzes leistungsfähiger KI-Gigafactories als Gegengewicht zu den US-Giganten ein bloßer Wunschtraum. (Bild: © NicoElNino - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/99/2b/992bf8039e0c0a2818d7c01508cc2fd5/0132147095v1.jpeg "Stephan Reitzenstein vor der Probenkammer der Elektronenstrahl-Lithographie-Anlage: Diese Anlage stellt die hochpräzise Nanostrukturen für skalierbare Quantenlichtquellen her. (Bild: Felix Noak)")
:quality(80)/p7i.vogel.de/wcms/2a/90/2a906642044a7ddb2a3c49db6f2e1d26/0132054740v1.jpeg "Der experimentelle, im 0,7-Nanometer-Verfahren hergestellte Chip in den Fingerspitzen eines IBM-Forschers. (Bild: IBM)")
:quality(80)/p7i.vogel.de/wcms/bb/84/bb848b79900a103b8aaed3207f1f1055/0132159005v1.jpeg "KI verändert die Wirtschaftlichkeit von Cloud-Infrastrukturen grundlegend. Wer Ressourcen weiterhin statisch bereitstellt, zahlt oft deutlich mehr als technisch erforderlich wäre. (Bild: © Zamrznuti tonovi - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/4d/ef/4def98d350a28359460e482100e1d3d8/0132138749v1.jpeg "V.l..: Georg Schmidt-Reindahl (Eplan), Marc Walter (Rittal), Uwe Scharf (Rittal), Tobias Funke (TOBOL), Cornelia Müller (Rittal) Steffen Schmidt (Rittal) und Philipp Müller (Rittal) (Bild: Rittal)")
:quality(80)/p7i.vogel.de/wcms/a9/a3/a9a38515d76d5d2bdbf552020689dd4c/0132133445v1.jpeg "Veraltete IT-Strukturen, steigende Sicherheitsanforderungen und moderne Workloads: Alles Gründe dafür, die Infrastruktur schrittweise zu modernisieren. Aber wie soll das gelingen, ohne den laufenden Betrieb zu gefährden? (Bild: © Chainarong - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/b5/d4/b5d418de82fbb8e8f06b04d5eced180a/0132015300v1.jpeg "Die KI soll in etwa fünf Jahren Energie-Optimierung, Predictive Maintenance, Ressourcenzuordnung , zum Beispiel von CPU, GPU und Bandbreite, orchestrieren können. Doch diese agentische Steuerungsebene wird nicht nur zum Produktivitätshebel, sondern auch zu einer hochprivilegierten Angriffsfläche. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/be/a9/bea9813088d28bae7b19799a194fe99c/0131951229v1.jpeg "Ewe hat seine Java-Umgebung über mehr als 100 Anwendungen und Zehntausende Desktop-Arbeitsplätze standardisiert. Nach Angaben des Unternehmens sanken dadurch die Java-Lizenzkosten um 60 Prozent. (Bild: © RomanR - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/1c/2e/1c2e0effc700eddefcf2264786aef800/0131879187v1.jpeg "Siemens erweitert sein Portfolio für industrielle KI bei der Verarbeitung von Produktionsdaten und bei der Automatisierung von Engineering-Prozessen. (Bild: Midjourney / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/74/74/7474bd5b4077a876d07eedacc3829cf1/0131673379v1.jpeg "Datacenter sind nicht nur eine Immobilie; sie sind heute Teil der Wärme- und Strom-Infrastruktur, sind als Daten- und Kommunikationsschlüssel systemrelevant und unterliegen damit den KRITIS-DACH- und NIS-2-Gesetzen sowie Reporting-Pflichten. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/d0/75/d075ceeb4de4543fd6446dd4b26825d2/0131796600v2.jpeg "Am 21. Mai 2026 hat Globa lFoundries den Geschäftszweig „Quantum Technology Solutions“ ins Leben gerufen, der zur Skalierung der Fertigungskapazitäten gedacht ist. Der Geschäftsbereich startet mit Kundenverträgen und einer Pipeline von Quanteninnovatoren, die darauf ausgerichtet sind, auf seiner Plattform zu skalieren, so Silicon Saxony. (Bild: frei lizenziert: Gerhard Altmann)")
:quality(80)/p7i.vogel.de/wcms/01/1e/011eecedd1890f96971d8c6334e59403/0131873319v2.jpeg "Das Bild visualisiert einen Zufallszahlengenerator, der auf Quantenfluktuationen beruht (Bild: Fraunhofer IPMS/KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/6f/b7/6fb7ad8acdc584a2bfb3b9c28ae5cc29/0131860924v1.jpeg "Auf dem „Optica Quantum Summit 2.0“ stellt das Unternehmen in Glasgow vor, wie sie optische Übertragung in den Rechenprozess integrieren. (Bild: © Chanelle M/peopleimages.com - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/29/33/2933cd5e834f8070b6c6777334e0aa0e/0131690146v1.jpeg "Wie Unternehmen mit ausgealterten Daten und IT-Hardware ümgehen, ist auch und nicht zuletzt eine Frage der Sicherheit. (Bild: © VladaToday - stock.adobe.com / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/16/3c/163ca34e83af8b229e3babcdfbdfeeaf/0131682376v1.jpeg "Zu sehen ist das Äußere des Halbleiter-Leistungsschalters „Sentron 3QD2“. (Bild: Siemens)")
:quality(80)/p7i.vogel.de/wcms/dd/0a/dd0a2e101153798711f788fdf4fdd7e0/0131888564v1.jpeg "Die Partnerschaft soll dazu dienen, parallelen Hochleistungszugriff mit automatisiertem Datenmanagement und skalierbarer Langzeitarchivierung für KI-, HPC- und Big-Data-Umgebungen zu kombinieren. (Bild: © Rawpixel.com - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/01/25/01259ecb55d6f67a5bc2b2c00b1b383e/0131864837v3.jpeg "Der Supercomputer „Alps“ basiert auf dem System dem „Cray-EX“ von HPE. (Bild: CC BY-SA 3.0 / cscs.ch)")
:quality(80)/p7i.vogel.de/wcms/bf/a9/bfa9522af622dfe0fca8fcf1ae0f157b/0131569943v1.jpeg "Das Huang signierte Rack steht übrigens nicht zum Verkauf. Michael Dell hat das auf der Bühne klargestellt. Manche Symbole sind zu wertvoll für den freien Markt. Doch die Partnerschaft zwischen Dell und Nvidia länger hält als manche Dating-Beziehung, wird sich zeigen. (Bild: Paula Breukel)")
:quality(80)/p7i.vogel.de/wcms/02/75/02759dd74c0a3c0df4d22999cae350a1/0132208640v1.jpeg "Eisenach bekommt kein Rechenzentrum mit 300 MVA Anschlussleistung. Obwohl das Vorhaben weit fortgeschritten war, hat der Stadtrat das Projekt nun vorerst gestoppt. (Bild: Eisenach / Charlotta Wasteson/cwasteson / CC BY 2.0 / flickr.com)")
:quality(80)/p7i.vogel.de/wcms/3e/76/3e762ad103dac4a62d81cc05d0e8d8d5/0132205485v1.jpeg "Strom, Fläche, kaum Gewerbesteuer: Microsofts vierter NRW-Standort sorgt für Ärger, noch bevor der erste Spatenstich erfolgt ist. (Bild: Microsoft / Julien G. / CC BY 2.0 / flickr.com)")
:quality(80)/p7i.vogel.de/wcms/08/f2/08f20bf156b8751027de9aa84b25db10/0131012870v1.jpeg "Daten von OpenStreetMap - Veröffentlicht unter ODbL (Bild: OpenStreetMap)")
:quality(80)/p7i.vogel.de/wcms/f3/da/f3dacd38e5834ae3f3c9d0a4bc9664d3/0113348475.jpeg "Das vom Umweltbundesamt beauftragte Projekt „Public Energy Efficiency Register of Data Centres “ (PeerDC), ist nach Einschätzung der Beteiligten Marina Köhn (UBA), Peter Radgen (IER Uni Stuttgart) und Felix Behrens (Öko-Institut e.V.) ein Erfolg auf ganzer Linie. Das sah DataCenter-Chefredakteurin Ulrike Ostler nach dem DataCenter-Diaries Podcast #16 nicht ganz so rosa. (Bild: sdecoret - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/90/f5/90f56ec6cb3ddbdabca2162fd5477836/0113078524.jpeg "(Bild: Vogel IT-Medien GmbH)")
:quality(80)/p7i.vogel.de/wcms/0f/09/0f097990002b7600075e43c92af4a3fd/0110524571.jpeg "(Bild: frei lizenziert/Krystsina Radzewich)")
:quality(80)/p7i.vogel.de/wcms/66/ae/66ae9e32738784b57e2ad8c1a4b0986f/0109756744.jpeg "Eines der in Deutschland befindlichen NTT-Datacenter - in Hattersheim - und das PeerDC-Logo. (Bild: NTT Global Data Centers )")
:quality(80)/p7i.vogel.de/wcms/e2/fc/e2fc5ae66726bf4e580099c75883d736/0132027377v2.jpeg "DIe Integration heterogener HPC-Umgebungen und digitale Souveränität waren wichtige Themen auf der Kongressmesse „ISC High Performance 2026“ in Hamburg. (Bild: Rüdiger)")
:quality(80)/p7i.vogel.de/wcms/95/b1/95b1b0fe6e64d17070e3a412b8e998e6/0132016666v1.jpeg "Die zweite Generation der photonischen Coprozessoren von Qant auf der „ISC High Performance 2026“. (Bild: Qant / Linkedin)")
:quality(80)/p7i.vogel.de/wcms/ee/3f/ee3f063b82737f0369c09ba7854587b5/0127234708v1.jpeg "Das sind die Gewinner der IT-Awards 2025! (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/f1/f0/f1f007a4518fa65d3cb0ea5ca465142a/0121300054v3.jpeg "Strahlende Gesichter bei allen, die die Preise des 10. DataCenter-Insider Award am gestrigen 17. Oktober abholen durften - in den Kategorien: Schnelles Interconnect, Infrastruktur der Resilienz, Coole Kühlung, HPC- und KI-Hardware, Grünes Co-Location und Cloud-native Plattformen. (Bild: Manuel Emme Fotografie)")
:quality(80)/p7i.vogel.de/wcms/a8/28/a828f76369267628d833a12c26dd6579/0121131534v3.jpeg "DataCenter-Insider verleiht heute die IT-Awards 2024 in sechs Kategorien. (Bild: Vogel IT-Medien)")
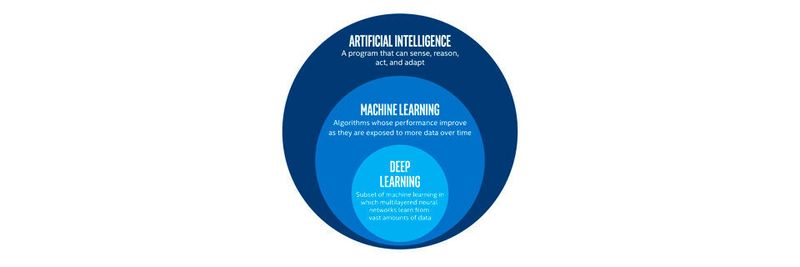
Big Data und Deep Learning So spürt Deep Learning Datenmuster auf
Die Zunahme an unstrukturierten Daten wie etwa Bildern, Blogs und Sprachbotschaften macht es ratsam, diese Massendaten automatisch erkennen zu lassen. Deep Learning, ein Unterbereich des Machine Learning, hilft bei der Erkennung dieser Daten und findet Muster in natürlicher Sprache, in Bildern und vielem mehr.
Anbieter zum Thema
Heute „sehen“ und „sprechen“ Computersysteme fast wie Menschen. Die Leistung wird vor allem durch die Rechner-Performance begrenzt. Da es immer mehr Menschen, Organisationen und Rechnersysteme gibt, die miteinander kommunizieren, reicht es längst nicht mehr aus, Menschen in die Erkennung solcher Mitteilungen und Botschaften einzubinden. Die Informationen müssen maschinell verarbeitet werden.
Im Jahre 1965 begannen die ersten Forscher damit, Maschinen beizubringen, Handschriften auf Postkarten und Briefen zu erkennen. Schnell tauchte das Problem der Genauigkeit und Treffsicherheit dieser „Optical Character Recognition“ (OCR) auf. Was heute auf fast jedem Tablet-PC zur Verfügung steht, bedeutete vor rund 50 Jahren einen erheblichen Aufwand an Rechenleistung, an intelligenten Algorithmen und vor allem an Methoden.
Die erste Lösung lautete: Die Systeme müssen selbst lernen und sich selbst optimieren. Das war die Geburtsstunde des Deep Learning.
Einsatzbereiche
Heute sehen wir durch die gewaltigen Fortschritte an Rechenleistung, wie groß die Vorteile sind, die Deep Learning (DL) mit sich bringen kann. Autos können heute autonom fahren, weil sie ihre Umgebung rasend schnell erkennen und interpretieren. Google Voice verleiht jedem PC und Smartphone die Fähigkeit, Spracheingaben in unzähligen Sprachen zu erkennen – nicht nur die natürliche Sprache, sondern auch die Ausdrucksweise eines individuellen Sprechers.
Das ist im Chinesischen, in dem die Bedeutung eines Ausdrucks mit der Tonhöhe wechselt, von besonderer Bedeutung. DL-Systeme erkennen inzwischen Gesichter, Gesichtsausdrücke und sogar Gefühlsausdrücke, also das Mienenspiel eines Menschen. Affektives Computing, wie die Gartner Group es nennt, ist beinahe schon marktreif.
:quality(80)/images.vogel.de/vogelonline/bdb/841900/841934/original.jpg "\"Chappie\", der Film von Sony Pictures mit Sigourney Weaver und Hugh Jackman, entstand ebenfalls unter Einsatz von GPUs und thematisiert selbstlernende Roboter. (Bild: Sony/Nvidia)")
Deep Learning funktioniert durch paralleles Rechnen
Nvidia, Chappie oder: Computer sind auch nur Menschen
Die Zahl der Anwendungsgebiete ist schier unendlich und reicht von der Betrugserkennung über Fahndungsmethoden bis hin zur Medizin und dem Transportwesen. DL-Algorithmen interpretieren nicht nur durch ihr selbstoptimierendes Lernen, sie geben zunehmend auch Handlungs- und Entscheidungsempfehlungen.
Die ultimative Prüfung für jedes DL-System ist der nach Alan Turing benannte Turing-Test: Gemessen wird, wie gut es einem rechnergestützten System gelingt, einen Menschen nachzuahmen. Wenn der Rechner nicht von einem Menschen (Verhalten, Ausdruck, Wahrnehmung un Ähnliches) zu unterscheiden ist, dann gilt der Test als bestanden.
:quality(80)/images.vogel.de/vogelonline/bdb/1130700/1130731/original.jpg "(Intel)")
:quality(80)/images.vogel.de/vogelonline/bdb/1130700/1130730/original.jpg "(Intel)")
Herausforderungen
Von perfekten Künstlichen Intelligenzen (KI) à la HAL 9000 in Stanley Kubricks Filmklassiker „2001 – Odyssee im Weltraum“ sind die heutigen Systeme noch weit entfernt. Das Gehirn verfügt durchschnittlich über 100 Milliarden Nervenzellen, der größte heutige Rechencluster bringt es nur auf eine Milliarde Knoten. Nicht nur das. Greg Diamos, leitender Forscher im AI Labor im Silicon Valley von Baidu, sagte in einem Interview und auf der International Supercomputing Conference 2016 in Frankfurt/Main: „Der Unterschied zwischen der nachhaltigen Rechenleistung des schnellsten RNN-Trainingssystems (Rekursives Neuronales Netzwerk), das wir bei Baidu kennen, und der theoretischen Spitzenleistung des schnellsten Computers der Welt liegt annähernd beim Faktor 2.500.“
Diamos spricht von Trainingssystemen und RNNs, also rekursiven Neuronalen Netzwerken. Sie sind die am meisten verbreiteten Grundlagen von Deep Learning. Es gibt andere Methoden, so etwa symbolische Verfahren im Text Mining, einer Disziplin des maschinellen Lernens.
Aber DL hat durch Artificial Neural Networks (ANN) seit 2006 einen großen Aufschwung erlebt und wird seit 2016 massiv von Intel, IBM und anderen Schwergewichten unterstützt. Aus einem esoterischen Forschungszweig wird endlich eine Volksindustrie.
Methoden
Eine der großen Herausforderungen beim Machine Learning ist das Auffinden von Merkmalen und das Entwickeln von Funktionen, um diese Suchen zu stützen. Der Programmierer muss dem Algorithmus mitteilen, wonach das System suchen soll, beispielsweise eine Handschrift auf einem Brief.
Den Rechner mit Rohdaten zu füttern, um ihn zu „trainieren“, erweist sich schnell als wenig zielführend. Denn selbst das Erkennen der Kategorie „Katze“ lässt den Rechner, der „sehen“ kann, auf so viele Unterschiede stoßen, dass er kaum zu einem Ergebnis gelangt. Die Treffsicherheit tendiert gegen Null.
Die vielen verschiedenen Modelle des Deep Learning gehen dieses Problem an, indem sie dem Rechner durch Gewichtung beibringen, auf welche Merkmale er sich konzentrieren soll. Wie im Machine Learning wird der Algorithmus fortwährend mit den neuen Ergebnissen gefüttert und kann sich theoretisch selbst optimieren, um seine Genauigkeit zu steigern. „Rekursive Neuronale Netzwerke sind Funktionen, die Sequenzen von Daten umwandeln, beispielsweise ein Audio-Signal in eine textliche Transkription, oder einen englischen Satz in einen chinesischen“, erläutert Greg Diamos. „Andere ANN arbeiten nicht mit Sequenzen (Tonsignale zum Beispiel), sondern mit Daten von fester Länge, zum Beispiel einem Bild mit festen Abmessungen.“
Lernen ist gar nicht einfach
Verschiedene DL-Modelle, die unter anderem in München und Zürich entwickelt wurden, steigern sowohl die Treffsicherheit als auch die Schnelligkeit. Aus Wochen werden Tage, bis ein Trainingslauf beendet ist, aus Tagen werden Stunden und so weiter, bis das Training beendet ist und der Algorithmus auf Testdaten angewandt werden kann. Wenn beispielsweise der Gefühlsausdruck in einem Social-Media-Eintrag analysiert werden soll (Sentiment Analysis), muss das DL-System auch Ironie und Sarkasmus erkennen können.
Neuronale Netze arbeiten in der Regel nicht nur sequenziell-linear wie im Batch Processing, sondern auch in Schichten. In den sechziger und siebziger Jahren gab es nur eine Handvoll Schichten. Dabei werden die Ergebnisse stets von den niederen Ebenen an die höheren Ebenen weitergereicht, damit ein höheres Maß an Abstraktion erzielt wird. Inzwischen werden Ergebnisse zurück oder vorausgeschickt, um das Training zu beschleunigen. Greg Diamos arbeitet heute bei Baidu an einem RNN mit mehreren tausend Schichten.
Aber es gibt, wie der entsprechende Wikipedia-Artikel erwähnt, schon Neuronale Netzwerke mit Millionen Schichten. Faustregel: Je komplizierter das Problem (etwa Erkennung von natürlicher Sprache sowie deren Übersetzung), desto mehr Schichten werden benötigt. Es ist eine Form der Parallelverarbeitung und erfordert entsprechende Kapazität, Programme und Entwickler.
Technologien: GPUs
Dass Deep Learning heutzutage vor allem in Rechenclustern abläuft, liegt, wie gesagt, an der benötigten Rechenleistung: Die Aufgabe wird auf viele verschiedene Rechner verteilt. Mit „Rechner“ sind allerdings zunehmend nicht mehr CPUs gemeint, sondern Grafikprozessoren – GPUs. Sie sind bislang viel besser in der Lage gewesen, Parallelverarbeitung zu erledigen.
Wie Greg Diamos schon erwähnte, ist bei einem Faktor 2.500 zwischen dem IST-Zustand und dem potenziellen Maximum noch eine Menge Luft nach oben. „Das Ziel unserer Arbeit besteht darin, die Skalierbarkeit im Hinblick auf das Trainieren unserer RNNs zu erhöhen, um diese Lücke zu schließen“, sagte er im Interview. Diamos kommt vom GPU-Hersteller Nvidia und kennt sich mit deren Mehrkern-Technik bestens aus.
„Wir gehen so vor, dass wir GPUs auf kleinen Arbeitseinheiten 30-mal effizienter machen, was eine höhere Skalierung erlaubt. Wir erzielen eine 16-fache Steigerung der ,starken' Skalierung, wenn wir von acht GPUs, die nicht unsere Technologie aufweisen, auf 128 GPUs umsteigen, die unsere Technologie besitzen. Unsere Implementierungen von 128 GPUs erhalten einen Zuwachs an Gleitkommarechenleistung (FLOP/s) aufrecht, verglichen mit 31 Prozent auf einer einzelnen GPU.“
Statt also durch Verteilung auf 128 GPUs an skalierbarer Leistung einzubüßen, sieht Diamos fast die gleiche Leistung wie auf einer Einzel-GPU. Er hoffe auf die Entwicklung eines Prozessors (CPU oder GPU), der die Leistung von 10 PetaFLOP/s bei einem Energieverbrauch von 300 Watt/h erbringt – oder die Leistung von 150 ExaFLOP/s bei 25 Megawatt/h. Alle am Supercomputing beteiligten Nationen, von der Schweiz bis Südafrika, sind an dieser Optimierung beteiligt. Der Stand der Dinge wird halbjährlich in der Top-500-Liste aktualisiert, die seit 2016 auch die energieeffizientesten Systeme aufführt.
Deep Learning im Cluster
Wie schon erwähnt, spielen Cluster eine zentrale Rolle im DL-relevanten Trainieren von Neuronalen Netzen. „Die Skalierung des Trainings auf große Clusters ermöglicht das Training von größeren Neuronalen Netzwerken für umfangreichere Datenmengen, als mit irgendeiner anderen Technologie möglich wäre“, fasst Diamos die Lage zusammen.
Glücklicherweise muss kein DL-Forscher mehr einen NN-Cluster selbst bauen, um eine DL-Framework programmieren zu können. „Caffe“ ist ein in der Open-Source-Gemeinde verbreitet genutztes DL-Framework des Berkeley Vision and Learning Center (BVLC). Sowohl Intel als auch IBM haben es in ihre jeweiligen AI-Plattformen integriert.
Caffe kann mit einer einzigen K40-GPU von Nvidia über 60 Millionen Bilder pro Tag verarbeiten. Das entspricht einer Millisekunde (ms) pro Bild für die Inferenz (Vorgabe des vermuteten Befundes) und 4 ms/Bild für die Lernphase.
Doch Caffe muss auf einem Cluster implementiert werden, um leistungsfähig zu sein. Die Universität von Toronto hat 2012 mit AlexNet [PDF] einen Durchbruch erzielt, wobei für die Bilderkennung wie bei Caffe GPUs genutzt wurden. Diese Leistung gilt heute zusammen mit Caffe und ImageNet als Benchmark.
Mittlerweile sind eine Reihe weiterer Neural Network Cluster entstanden, und der Interessent sollte sich informieren, welche überhaupt von seinem bevorzugten Technologielieferanten unterstützt werden. Sie tragen fantasievolle Namen wie Theano, TensorFlow, Torch sowie Apache Singa. Es kann durchaus sein, dass ein Hersteller sein eigenes Süppchen kocht. Das zeigt sich bei den Ankündigungen von Mitte November 2016.
Neuheiten: Intel Nervana
Intel hat am 17. November 2016 seine KI-Plattform vorgestellt: Nervana. Was vorher ein bekannter NN-Cluster war, soll nun performante AI-Lösungen ermöglichen. Der Nervana Graph Compiler stellt NN-Topologien dar und optimiert sie, das Intel DL SDK erlaubt die Erstellung von App auf dem gewählten Framework. Die Software kommt von Nervanas DL-Framework Neon .

Die Hardware stellen die Xeon-CPUs, die Xeon-Phi-Koprozessoren und FPGAs (field-programmable gate arrays). Dafür werden zwei Chips entwickelt. „Lake Crest“ ist ein Chip, der hohe Rechenleistung für DL-NNs mit großer Bandbreite vereint, und „Knight's Mill“ ist ein Xeon-Phi-Prozessor, der die bisherige DL-Leistung vervierfachen soll.
Auch die nächste Xeon-Generation, die den Codenamen Skylake trägt, soll Mitte 2017 mit der Technologie AVX-512 eine erhebliche Beschleunigung der Inferenz-Prozesse im Machine Learning erlauben. Was Intel demonstrieren will: Deep Learning ist keine Domäne der GPUs, sondern CPUs können hier ebenfalls punkten, besonders wenn sie über Intels Math Kernel Library MKL und die Data Analytics Acceleration Library DAAL verfügen.
Intel Saffron ist eine Cognitive-Computing-Lösung, die auf In-memory-Reasoning-Prozesse setzt, die auf heterogene Daten angewandt werden. Was ähnlich etwa wie IBM Watson klingt, soll aber auch Platz in kleinen Geräten wie Smartphones und IoT-Endgeräten finden. Entsprechende Programmierschnittstellen sollen unter andrem in Intel-Geräten wie der 3D-Kamera RealSense ihren „Sehnerv“, unterstützen.
Intel beschreibt Movidus wie folgt: „Movidius bietet energiesparende High-Performance-System-on-Chip- Plattformen an, mit deren Hilfe Bildverarbeitungsanwendungen beschleunigt werden können. Zudem werden von Movidius Algorithmen bereitgestellt, die speziell auf die Bereiche Deep Learning, Depth Processing, Navigation und Kartierung sowie natürliche Interaktion ausgelegt sind und haben breites Know-how bei Embedded Computer Visions und Machine Intelligence.“

Neuheiten: IBM Power AI
Die IBM charakterisiert ihre ebenfalls Mitte November vorgestellte Plattform „PowerAI“ als Lösung aus Hard- und Software, „die die doppelte Rechenleistung im Vergleich zu vergleichbaren Servern mit vier GPUs bietet, auf denen AlexNet mit Caffe ausgeführt wird.“ Die gleiche Konfiguration soll auch Konfigurationen aus acht GPU-basierten x86-Servern rechts überholen können, solange die IBM-eigene POWER8+-CPU verwendet wird.
PowerAI unterstützt fünf AI-Frameworks, darunter Caffe und Theano. Ebenso wichtig sind die Programmierbibliotheken im Toolkit. Es sind GPU-DL-Libraries für cuDNN, cuBAS und NCCL als Bestandteile des Nvidia-SDKs. Sie sollen es Apps ermöglichen, die Beschleunigung mehrerer GPUs auf den aktuellen, optimierten IBM-Servern der Reihe S822LC zu nutzen (L steht für „Linux“, C für „Cloud“). Die Linux-Distributionen der Wahl sind hierbei RHEL, SLES und Ubuntu 14.4. Für Kunden mit S822LC ist PowerAI kostenlos. Das Toolkit lasse sich auf einem Einzel-Server ausführen wie auch auf großen Supercomputing-Clustern.
Ausblick
Intel will die Leistung von DL-Frameworks binnen dreier Jahre ab 2017 um den Faktor 100 steigern. Intels CEO Brian Krzanich verspricht eine „AI-Revolution“, die in den Startlöchern steht, um die Gesellschaft zu verbessern, sei es in der Krebserkennung, in der Genomforschung, im Bergbau, in der Ausbildung – oder im eingangs erwähnten autonomen Fahren.
Was für IBM Cognitive Computing auf Watson-Basis, das ist bei Intel ein umfassendes Chip- und Software-basiertes Ökosystem von Technologien mit der Bezeichnung „Nervana“. Intel reklamiert 80 Prozent Marktanteil im High Performance Computing für sich und unterstützt kleine Endgeräte sowie IoT. IBM setzt vor allem seine Power-CPU für Server und die Open Power Plattform. Der Interessent hat also immerhin klare Wahlmöglichkeiten.
(ID:44427863)
:quality(80)/p7i.vogel.de/wcms/7f/39/7f3904c8e34848303d65dcb8fa84bef0/0126326548v1.jpeg "Im Bild: Die Kühlanlagen auf dem Dach des „Modular Data Centre“, in dem „Jupiter“untergebracht ist. Mit mehr als 60 Milliarden Rechenoperationen pro Watt ist Jupiter der effizienteste unter den fünf leistungsfähigsten Superrechnern der Welt. (Bild: Forschungszentrum Jülich/Sascha Kreklau)")
:quality(80)/p7i.vogel.de/wcms/02/5e/025e747e4415dd1eefc87949c8880b80/0130120048v2.jpeg "Der Prozessor „Intel Xeon 6“ kann als Host-CPU in „DGX Rubin NVL8“-Systemen von Nvidia zum Einsatz kommen. (Bild: Intel)")