
:quality(80)/p7i.vogel.de/wcms/06/cf/06cf257e61ccd436973f284ed83f043a/0132332086v1.jpeg "Wenn Rechenzentren ihren Stromhunger bewältigen können, müssen sie starke Partnerschaften mit Energieversorgern eingehen. (Bild: Daniel Shrader / GPT Image 2 / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/4f/77/4f7777f92f554a389bd71de1adf53194/0132279450v1.jpeg "Innovation wird nicht allein durch kleinere Transistoren, neue Knoten-Geometrien oder leistungsstärkere GPUs vorangetrieben. Geätzte Durchflussplatten und Hochleistungswärmetauscher bilden einen entscheidenden, wenn auch oft unsichtbaren Teil des KI-Ökosystems. (Bild: Precision Micro)")
:quality(80)/p7i.vogel.de/wcms/0b/39/0b3998ee8075174ec8d14d166ff53bb3/0132267144v1.jpeg "Dell Technologies erweitert sein Portfolio für KI- und HPC-Infrastrukturen um eine Rack-Scale-Plattform mit hoher GPU-Dichte. (Bild: © Gorodenkoff - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/ff/93/ff93dfcd6be86bedcea495f48574316b/0132223732v1.jpeg "Abwärme aus Bestandsrechenzentren? Ja, das geht, sagt Ralph Hintemann vom Borderstep Institut. (Bild: Midjourney / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/08/1a/081a7876f47ad1a1dbbaee94e9715a41/0132260078v1.jpeg "Warum KI-Agenten kein Selbstläufer sind: Agentische KI-Workflows stellen unterschiedliche Anforderungen an Rechenzentrums-Hardware. (Bild: © SVasco - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/d4/3b/d43b7836de769e65b766932925d2ef40/0132242200v1.jpeg "KI-Cluster benötigen leistungsfähige Interconnects, damit tausende GPUs mit geringer Latenz und hoher Bandbreite zusammenarbeiten können. (Bild: Midjourney / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/bb/84/bb848b79900a103b8aaed3207f1f1055/0132159005v1.jpeg "KI verändert die Wirtschaftlichkeit von Cloud-Infrastrukturen grundlegend. Wer Ressourcen weiterhin statisch bereitstellt, zahlt oft deutlich mehr als technisch erforderlich wäre. (Bild: © Zamrznuti tonovi - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/4d/ef/4def98d350a28359460e482100e1d3d8/0132138749v1.jpeg "V.l..: Georg Schmidt-Reindahl (Eplan), Marc Walter (Rittal), Uwe Scharf (Rittal), Tobias Funke (TOBOL), Cornelia Müller (Rittal) Steffen Schmidt (Rittal) und Philipp Müller (Rittal) (Bild: Rittal)")
:quality(80)/p7i.vogel.de/wcms/a9/a3/a9a38515d76d5d2bdbf552020689dd4c/0132133445v1.jpeg "Veraltete IT-Strukturen, steigende Sicherheitsanforderungen und moderne Workloads: Alles Gründe dafür, die Infrastruktur schrittweise zu modernisieren. Aber wie soll das gelingen, ohne den laufenden Betrieb zu gefährden? (Bild: © Chainarong - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/be/a9/bea9813088d28bae7b19799a194fe99c/0131951229v1.jpeg "Ewe hat seine Java-Umgebung über mehr als 100 Anwendungen und Zehntausende Desktop-Arbeitsplätze standardisiert. Nach Angaben des Unternehmens sanken dadurch die Java-Lizenzkosten um 60 Prozent. (Bild: © RomanR - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/1c/2e/1c2e0effc700eddefcf2264786aef800/0131879187v1.jpeg "Siemens erweitert sein Portfolio für industrielle KI bei der Verarbeitung von Produktionsdaten und bei der Automatisierung von Engineering-Prozessen. (Bild: Midjourney / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/74/74/7474bd5b4077a876d07eedacc3829cf1/0131673379v1.jpeg "Datacenter sind nicht nur eine Immobilie; sie sind heute Teil der Wärme- und Strom-Infrastruktur, sind als Daten- und Kommunikationsschlüssel systemrelevant und unterliegen damit den KRITIS-DACH- und NIS-2-Gesetzen sowie Reporting-Pflichten. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/99/2b/992bf8039e0c0a2818d7c01508cc2fd5/0132147095v1.jpeg "Stephan Reitzenstein vor der Probenkammer der Elektronenstrahl-Lithographie-Anlage: Diese Anlage stellt die hochpräzise Nanostrukturen für skalierbare Quantenlichtquellen her. (Bild: Felix Noak)")
:quality(80)/p7i.vogel.de/wcms/d0/75/d075ceeb4de4543fd6446dd4b26825d2/0131796600v2.jpeg "Am 21. Mai 2026 hat Globa lFoundries den Geschäftszweig „Quantum Technology Solutions“ ins Leben gerufen, der zur Skalierung der Fertigungskapazitäten gedacht ist. Der Geschäftsbereich startet mit Kundenverträgen und einer Pipeline von Quanteninnovatoren, die darauf ausgerichtet sind, auf seiner Plattform zu skalieren, so Silicon Saxony. (Bild: frei lizenziert: Gerhard Altmann)")
:quality(80)/p7i.vogel.de/wcms/01/1e/011eecedd1890f96971d8c6334e59403/0131873319v2.jpeg "Das Bild visualisiert einen Zufallszahlengenerator, der auf Quantenfluktuationen beruht (Bild: Fraunhofer IPMS/KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/6f/b7/6fb7ad8acdc584a2bfb3b9c28ae5cc29/0131860924v1.jpeg "Auf dem „Optica Quantum Summit 2.0“ stellt das Unternehmen in Glasgow vor, wie sie optische Übertragung in den Rechenprozess integrieren. (Bild: © Chanelle M/peopleimages.com - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/29/33/2933cd5e834f8070b6c6777334e0aa0e/0131690146v1.jpeg "Wie Unternehmen mit ausgealterten Daten und IT-Hardware ümgehen, ist auch und nicht zuletzt eine Frage der Sicherheit. (Bild: © VladaToday - stock.adobe.com / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/16/3c/163ca34e83af8b229e3babcdfbdfeeaf/0131682376v1.jpeg "Zu sehen ist das Äußere des Halbleiter-Leistungsschalters „Sentron 3QD2“. (Bild: Siemens)")
:quality(80)/p7i.vogel.de/wcms/b5/83/b5839e142c423a47b42433550f6ebbb5/0132253961v1.jpeg "Spezialisierte Neoclouds bieten einen scharfen KI-Fokus und suchen sich damit von dem breiten Portfolio der Hyperscaler abzusetzen. Ihr Marktanteil wächst beständig. (Bild: Daniel Schrader / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/25/ba/25ba46cb0d57f75776466da277dac3ff/0132182757v1.jpeg "Mit steigender GPU-Dichte wachsen auch die Anforderungen an die Leistungsfähigkeit und Skalierbarkeit der Storage-Infrastruktur. (Bild: © Gorodenkoff - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/dd/0a/dd0a2e101153798711f788fdf4fdd7e0/0131888564v1.jpeg "Die Partnerschaft soll dazu dienen, parallelen Hochleistungszugriff mit automatisiertem Datenmanagement und skalierbarer Langzeitarchivierung für KI-, HPC- und Big-Data-Umgebungen zu kombinieren. (Bild: © Rawpixel.com - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/f7/b6/f7b601cc2d73532d3cf1e28b2d3ef05d/0132349366v1.jpeg "Spanien gewinnt als Rechenzentrumsstandort weiter an Bedeutung. Projekte entstehen längst nicht mehr nur im Raum Madrid, sondern auch in weiteren Regionen des Landes. (Bild: © leonidkos - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/cb/c3/cbc3857e412dc55d28a9049bed41e453/0132347963v1.jpeg "Der KI-Campus Hyperion in Richland Parish zählt mit den geplanten fünf Gigawatt (GW) zu den größten Rechenzentrumsprojekten weltweit. (Bild: Meta)")
:quality(80)/p7i.vogel.de/wcms/64/a2/64a2bae810066a364cf9b28b0d6c171a/0132292701v1.jpeg "Symbolbild aus Berlin-Mitte: Die Bürgerinitiative Rechenzentrum Kronstorf hat für den 17. Juli eine Demonstration gegen den geplanten Ausbau des Google-Rechenzentrums angekündigt. (Bild: F* Google / Hossam el-Hamalawy / CC BY-SA 2.0 / flickr.com)")
:quality(80)/p7i.vogel.de/wcms/16/ae/16aee1b5f9e1992291b7d7cfba63e956/0132282477v1.jpeg "Der Flugplatz Köthen ist Geschichte: Seit Oktober 2025 landet hier kein Flugzeug mehr. Wimex will auf dem Gelände ein Rechenzentrum bauen. (Bild: planes viewed from gateway bridge 02-06-2013 (13) / bert knottenbeld/bertknot / CC BY-SA 2.0 / flickr.com)")
:quality(80)/p7i.vogel.de/wcms/f3/da/f3dacd38e5834ae3f3c9d0a4bc9664d3/0113348475.jpeg "Das vom Umweltbundesamt beauftragte Projekt „Public Energy Efficiency Register of Data Centres “ (PeerDC), ist nach Einschätzung der Beteiligten Marina Köhn (UBA), Peter Radgen (IER Uni Stuttgart) und Felix Behrens (Öko-Institut e.V.) ein Erfolg auf ganzer Linie. Das sah DataCenter-Chefredakteurin Ulrike Ostler nach dem DataCenter-Diaries Podcast #16 nicht ganz so rosa. (Bild: sdecoret - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/90/f5/90f56ec6cb3ddbdabca2162fd5477836/0113078524.jpeg "(Bild: Vogel IT-Medien GmbH)")
:quality(80)/p7i.vogel.de/wcms/0f/09/0f097990002b7600075e43c92af4a3fd/0110524571.jpeg "(Bild: frei lizenziert/Krystsina Radzewich)")
:quality(80)/p7i.vogel.de/wcms/66/ae/66ae9e32738784b57e2ad8c1a4b0986f/0109756744.jpeg "Eines der in Deutschland befindlichen NTT-Datacenter - in Hattersheim - und das PeerDC-Logo. (Bild: NTT Global Data Centers )")
:quality(80)/p7i.vogel.de/wcms/ad/1c/ad1ca8d7eab7d0c398db520687586a57/0132253970v1.jpeg "SNP, die schottische Regierungspartei, hatte sich noch Anfang 2026 gegen ein Datacenter-Moratorium ausgesprochen. Jetzt vollzieht sie eine Kehrtwende, sodass in Holyrood eine Mehrheit für ein temporäres Bauverbot möglich wird. (Bild: Yves Grandmontagne /DCmag)")
:quality(80)/p7i.vogel.de/wcms/ee/3f/ee3f063b82737f0369c09ba7854587b5/0127234708v1.jpeg "Das sind die Gewinner der IT-Awards 2025! (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/f1/f0/f1f007a4518fa65d3cb0ea5ca465142a/0121300054v3.jpeg "Strahlende Gesichter bei allen, die die Preise des 10. DataCenter-Insider Award am gestrigen 17. Oktober abholen durften - in den Kategorien: Schnelles Interconnect, Infrastruktur der Resilienz, Coole Kühlung, HPC- und KI-Hardware, Grünes Co-Location und Cloud-native Plattformen. (Bild: Manuel Emme Fotografie)")
:quality(80)/p7i.vogel.de/wcms/a8/28/a828f76369267628d833a12c26dd6579/0121131534v3.jpeg "DataCenter-Insider verleiht heute die IT-Awards 2024 in sechs Kategorien. (Bild: Vogel IT-Medien)")
Daten auf GPFS-Clustersystemen speichern Das IBM General Parallel File System im Big-Data-Einsatz
Geht es um die optimale und leistungsstarke Speicherung von Daten, müssen sich Administratoren Gedanken um das eingesetzte Dateisystem machen. Einer der wichtigsten Vertreter in diesem Bereich ist das „General Parallel File System“ (GPFS) von IBM.
Anbieter zum Thema
:fill(fff,0)/p7i.vogel.de/companies/64/e4/64e4be0db6ddc/rittal-4c-w.png "rittal-4c-w (Rittal GmbH & Co. KG)")
:fill(fff,0)/p7i.vogel.de/companies/65/65/6565ddb7b8418/dcg-wort-bild-marke-dark-rgb.jpeg "dcg-wort-bild-marke-dark-rgb (DC-Datacenter-Group GmbH)")
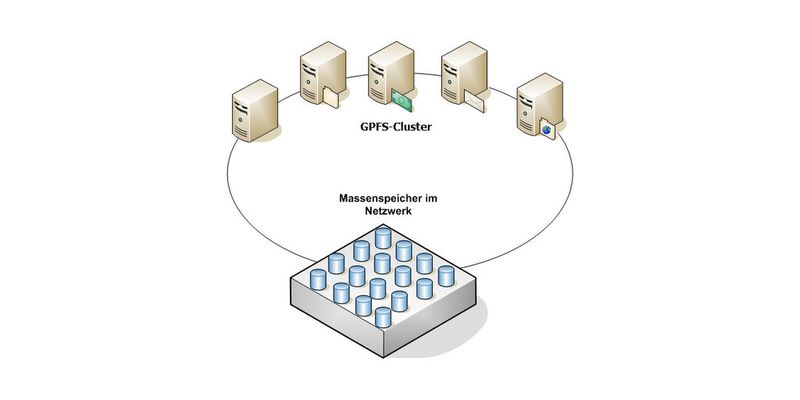
GPFS ist für die Betriebssysteme AIX und Linux verfügbar. Entstanden ist das Dateisystem 1998, seitdem wurde es ständig weiterentwickelt. Bei GPFS handelt es sich – wie beim Hadoop Distributed Filesystem (HDFS) – um ein paralleles Dateisystem. Bei solchen Dateisystemen sind die Daten auf den Cluster-Knoten Server-weit verfügbar, das heißt: Server können auf alle Datenträger im Cluster schreibend zugreifen. GPFS ermöglicht in diesem Bereich sogar Zugriffe über LAN-Leitungen, auch wenn keine direkte Verbindung eines Serverknotens zum Storage-Gerät verfügbar ist.
Diese Systeme können daher Daten auf mehrere Datenträger verteilen und bieten einen sehr hohen E/A-Durchsatz. GPFS liefert eine hohe Leistung beim sequenziellen Zugriff auf große Dateien. In Echtzeit können also Dutzende Server auf die gleichen Daten schreibend und lesend zugreifen. Die Daten bleiben immer konsistent.
Die Daten werden über ein Client-Node-Server-Node-System verteilt, welches typisch für den Einsatz von Big-Data-Szenarien, wie im Falle von Hadoop. GPFS kann Berechnungen auf verschiedene Server verteilen, was ideal für Hadoop ist.
Theoretisch bietet GPFS die Möglichkeit, Tausende Knoten in einem Cluster zusammenzufassen. Funktionen wie Striping (RAID 0) und Mirorring (RAID 1) sind bereits im Dateisystem enthalten. Die Steuerung und Verwaltung des GPFS-Clusters wird von einem zentralen Server im Cluster übernommen. Die Knoten selbst können überall verteilt sein, je schneller die Datenverbindung, umso schneller ist die Datenverarbeitung.
(ID:43087542)
:quality(80)/p7i.vogel.de/wcms/0e/86/0e860e446618cfd46150e1695a0e052d/0129250866v2.jpeg "„Puppy Linux“ lässt sich gut als Live-System nutzen. (Bild: Thomas Joos)")
:quality(80)/p7i.vogel.de/wcms/7a/c6/7ac69d9e28f243679d676f81c0edf66e/0128327846v2.jpeg "Den „Proxmox Datacenter Manger“ gibt es jetzt in einer ersten stabilen Version. (Bild: Proxmox Datacenter Manager Datasheet)")