
:quality(80)/p7i.vogel.de/wcms/f9/e6/f9e6d7178831f3a939f6cb722e21007f/0132594477v1.jpeg "Redundanz kann ein Sicherheitsgefühl vermitteln, während ungeprüfte Infrastruktur und Notfallprozesse sowie physische und digitale Angriffsrisiken diesen Schein signifikant bedrohen. (Bild: Daniel Schrader / GPT-Image 2 / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/20/a1/20a1347bae821ee294285a2408de3cdb/0132508336v1.jpeg "Der Betreiber setzt bei Rechenzentren auf Ökostrom und Daten in Deutschland. (Bild: Pfalzkom)")
:quality(80)/p7i.vogel.de/wcms/06/50/06506387ede0e72e8d404494a3b9f2b1/0132511022v1.jpeg "KI-Infrastruktur und Rechenzentrumssystems treiben laut Gartner das weltweite IT-Ausgabenwachstum 2026 maßgeblich an. (Bild: © jamesteohart - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/8b/ae/8baee103debba73f2362593fc17d79fc/0132543354v1.jpeg "PUE zeigt Effizienz. Intelligente Laststeuerung entscheidet darüber, wie viel Rechenleistung ein Standort aus seiner verfügbaren Energie- und Netzkapazität herausholt, so Torge Lahrsen. (Bild: Daniel Schrader / GPT Image 2 / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/44/3a/443a4cb166a005757c21dd48a5ae8a26/0132505426v1.jpeg "CPU, GPU, Netzwerk und Software stammen aus dem AMD-Portfolio. Gemeinsam mit Supermicro entsteht eine durchgängige Infrastruktur für KI-Training und Inferenz. (Bild: Gemini / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/e8/d4/e8d462ed9972be2b8464c790cce263c0/0132429621v1.jpeg "Die Integration der KI-gestützten Designexploration von Precision Innovations soll die Silizium-Chip-Entwicklung beschleunigen, so Siemens. (Bild: Siemens)")
:quality(80)/p7i.vogel.de/wcms/37/0a/370aa88021e97f80526e1d07f8a64ca9/0132435873v1.jpeg "Die „ND MI455X v7“-Serie basiert auf AMDs Rackscale-Design und soll Reasoning- und Suchanwendungen sowie KI-Agenten in Azure beschleunigen. (Bild: Midjourney / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/0b/0e/0b0ef1fc1c379ab914c58f63a1ea58be/0132441193v1.jpeg "Storage-Schichten, geo-verteilte Datenhaltung und offene Standards sind die Grundlage für resiliente und souveräne Infrastrukturen. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/67/c3/67c399c0d42006c206b19ca13a408732/0132302716v1.jpeg "AI Restacking integriert Künstliche Intelligenz in alle Ebenen der Unternehmensarchitektur. Geschäftsprozesse, Daten, Anwendungen und Technologien bilden dabei ein vernetztes System, das kontinuierlich aus Daten und Feedback lernt. (Bild: © BalanceFormCreative - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/73/8d/738d892859c9bf552bffeaee476c1bc3/0132416407v1.jpeg "Die Architektur soll KI-Inferenz, Container und virtuelle Maschinen an dezentralen Standorten sichern. (Bild: © Starmarpro - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/bb/84/bb848b79900a103b8aaed3207f1f1055/0132159005v1.jpeg "KI verändert die Wirtschaftlichkeit von Cloud-Infrastrukturen grundlegend. Wer Ressourcen weiterhin statisch bereitstellt, zahlt oft deutlich mehr als technisch erforderlich wäre. (Bild: © Zamrznuti tonovi - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/be/a9/bea9813088d28bae7b19799a194fe99c/0131951229v1.jpeg "Ewe hat seine Java-Umgebung über mehr als 100 Anwendungen und Zehntausende Desktop-Arbeitsplätze standardisiert. Nach Angaben des Unternehmens sanken dadurch die Java-Lizenzkosten um 60 Prozent. (Bild: © RomanR - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/1c/2e/1c2e0effc700eddefcf2264786aef800/0131879187v1.jpeg "Siemens erweitert sein Portfolio für industrielle KI bei der Verarbeitung von Produktionsdaten und bei der Automatisierung von Engineering-Prozessen. (Bild: Midjourney / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/95/a7/95a74d5f20e7e05ab33efde3fdfb1008/0132474712v3.jpeg "Auf der \"ISC High Performance 2026\" präsentierten zahlreiche Hersteller neue Quantencomputer sowie Software und Integrationslösungen für hybride HPC-Umgebungen. (Bild: Alice&Bob)")
:quality(80)/p7i.vogel.de/wcms/63/38/63389b116419fdfba92da2a91ad4c4d2/0132481063v1.jpeg "Fehlende Rechenkapazitäten, geringe Investitionen und internationale Abhängigkeiten bremsen den Aufbau einer europäischen Quantenindustrie. (Bild: Midjourney / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/99/2b/992bf8039e0c0a2818d7c01508cc2fd5/0132147095v1.jpeg "Stephan Reitzenstein vor der Probenkammer der Elektronenstrahl-Lithographie-Anlage: Diese Anlage stellt die hochpräzise Nanostrukturen für skalierbare Quantenlichtquellen her. (Bild: Felix Noak)")
:quality(80)/p7i.vogel.de/wcms/d0/75/d075ceeb4de4543fd6446dd4b26825d2/0131796600v2.jpeg "Am 21. Mai 2026 hat Globa lFoundries den Geschäftszweig „Quantum Technology Solutions“ ins Leben gerufen, der zur Skalierung der Fertigungskapazitäten gedacht ist. Der Geschäftsbereich startet mit Kundenverträgen und einer Pipeline von Quanteninnovatoren, die darauf ausgerichtet sind, auf seiner Plattform zu skalieren, so Silicon Saxony. (Bild: frei lizenziert: Gerhard Altmann)")
:quality(80)/p7i.vogel.de/wcms/a9/a3/a9a38515d76d5d2bdbf552020689dd4c/0132133445v1.jpeg "Veraltete IT-Strukturen, steigende Sicherheitsanforderungen und moderne Workloads: Alles Gründe dafür, die Infrastruktur schrittweise zu modernisieren. Aber wie soll das gelingen, ohne den laufenden Betrieb zu gefährden? (Bild: © Chainarong - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/01/1e/011eecedd1890f96971d8c6334e59403/0131873319v2.jpeg "Das Bild visualisiert einen Zufallszahlengenerator, der auf Quantenfluktuationen beruht (Bild: Fraunhofer IPMS/KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/29/33/2933cd5e834f8070b6c6777334e0aa0e/0131690146v1.jpeg "Wie Unternehmen mit ausgealterten Daten und IT-Hardware ümgehen, ist auch und nicht zuletzt eine Frage der Sicherheit. (Bild: © VladaToday - stock.adobe.com / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/ab/65/ab65db7e99df89b1b486f75c13496180/0132419758v1.jpeg "Rechenzentrum ist nicht gleich Cloud. Über die Unterschiede zwischen Colocation und Cloud-Diensten und weshalb der Zugriff auf Daten wichtiger ist als der Standort der Infrastruktur. (Bild: Midjourney / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/de/01/de011e022cf7a4457aa686dfe2f20755/0132592633v1.jpeg "Blick auf's Kraftwerk Staudinger 2019: Hier plant Uniper die Entwicklung eines Rechenzentrumscampus mit Energieinfrastruktur. (Bild: Kraftwerk Staudinger - power plant Staudinger / Alban.py / CC BY-SA 2.0 / flickr.com)")
:quality(80)/p7i.vogel.de/wcms/47/67/47674acc2bfaf7b633e6a27e5796a056/0132591049v1.jpeg "Das Rechenzentrum in Ohio entsteht nicht im Eigentum von OpenAI. Der Konzern übernimmt vor allem die Rolle des langfristigen Mieters und Koordinators. (Bild: Midjourney / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/dd/3e/dd3e2627864aea6931a85a604ecb9048/0132529570v1.jpeg "Gießen von oben: Im Industriegebiet „Katzenfeld“ soll ein Rechenzentrum entstehen. Was bislang bekannt ist. (Bild: THM Gießen / atxcowboy / CC BY-SA 2.0 / flickr.com)")
:quality(80)/p7i.vogel.de/wcms/48/fa/48fae955ace458bfeb45fb69c5f1cf83/0132525775v1.jpeg "Helmut Kohl spricht sich für einen stärker dezentralen Ausbau der Rechenzentrumslandschaft aus. (Bild: Midjourney / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/f3/da/f3dacd38e5834ae3f3c9d0a4bc9664d3/0113348475.jpeg "Das vom Umweltbundesamt beauftragte Projekt „Public Energy Efficiency Register of Data Centres “ (PeerDC), ist nach Einschätzung der Beteiligten Marina Köhn (UBA), Peter Radgen (IER Uni Stuttgart) und Felix Behrens (Öko-Institut e.V.) ein Erfolg auf ganzer Linie. Das sah DataCenter-Chefredakteurin Ulrike Ostler nach dem DataCenter-Diaries Podcast #16 nicht ganz so rosa. (Bild: sdecoret - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/90/f5/90f56ec6cb3ddbdabca2162fd5477836/0113078524.jpeg "(Bild: Vogel IT-Medien GmbH)")
:quality(80)/p7i.vogel.de/wcms/0f/09/0f097990002b7600075e43c92af4a3fd/0110524571.jpeg "(Bild: frei lizenziert/Krystsina Radzewich)")
:quality(80)/p7i.vogel.de/wcms/66/ae/66ae9e32738784b57e2ad8c1a4b0986f/0109756744.jpeg "Eines der in Deutschland befindlichen NTT-Datacenter - in Hattersheim - und das PeerDC-Logo. (Bild: NTT Global Data Centers )")
:quality(80)/p7i.vogel.de/wcms/b6/2f/b62f5450fa983d6fba21ec3b64a51be3/0132542976v1.jpeg "Wenn man neben dem täglichen Betrieb die Lieferketten von Komponenten und die Bauaktivitäten misst, erscheint der Emissionsbeitrag von Rechenzentren in einem ganz anderen Licht, so Alliance Research. (Bild: Daniel Schrader / GPT Image 2 / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/ee/3f/ee3f063b82737f0369c09ba7854587b5/0127234708v1.jpeg "Das sind die Gewinner der IT-Awards 2025! (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/f1/f0/f1f007a4518fa65d3cb0ea5ca465142a/0121300054v3.jpeg "Strahlende Gesichter bei allen, die die Preise des 10. DataCenter-Insider Award am gestrigen 17. Oktober abholen durften - in den Kategorien: Schnelles Interconnect, Infrastruktur der Resilienz, Coole Kühlung, HPC- und KI-Hardware, Grünes Co-Location und Cloud-native Plattformen. (Bild: Manuel Emme Fotografie)")
:quality(80)/p7i.vogel.de/wcms/a8/28/a828f76369267628d833a12c26dd6579/0121131534v3.jpeg "DataCenter-Insider verleiht heute die IT-Awards 2024 in sechs Kategorien. (Bild: Vogel IT-Medien)")
Die kleine vSphere-6.5-Schule, Teil 2 - Text und Video vSphere HA wird intelligenter
Die Neuerungen in „VMware vSphere 6.5“ verteilen sich auf alle Komponenten der Produkt-Suite, „ESXi-Hypervisor“, „vCenter Server“, „PowerCLI“ und „vSAN“. Dieser Beitrag befasst sich mit den Neuerungen in vSphere 6.5, speziell den Cluster-Features.
Anbieter zum Thema
Zu den herausragenden Neuerungen des ESXi-Hypervisors gehören jene im Bereich der „Cluster-Features“ an erster Stelle die klassische High Availability Funktion, nicht zu verwechseln mit dem „vCenter-High-Availability-Feature“, das ebenfalls neu in vSphere 6.5 ist.
Die Neuerungen im Bereich HA sind in erster Linie funktionaler Natur und ziehen daher automatisch eine Erweiterung/Anpassung der zugehörigen GUI-Dialoge im Web-Client nach sich. VMware hat seinen Web-Client was die Logik und „Dramaturgie“ vieler Dialoge angeht aber auch grundsätzlich überarbeitet, was die gesamte HA-Konfiguration übersichtlicher macht.
Folgendes Video demonstriert die wichtigsten HA-Neuerungen in vSphere 6.5.
vSphere Admission Control
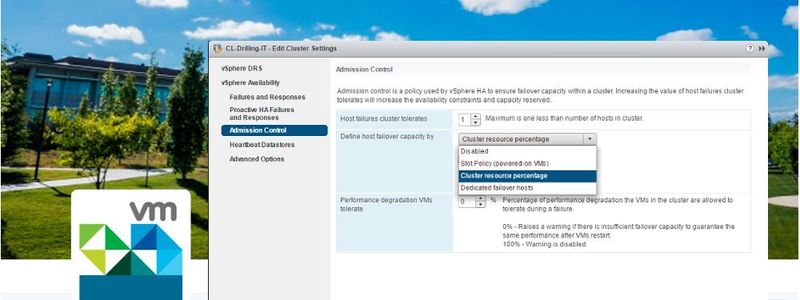
Die interessantesten HA-Erweiterung finden sich im Bereich der so genannten Zugriffssteuerung. Hierbei geht es darum, wie ESXi die benötigte Failover-Kapazität auf den einzelnen Hosts berechnet. Das können Admins mit einer Reihe von Policies steuern, sofern sie nicht einen ESXi-Host explizit und ausschließlich als Failover-Host betreiben möchten. Aufgrund der Architektur eines vSphere-HA-Cluster-Modells ist dies jedoch nicht zwingend und sie können jeden ESXi-Host im Cluster auch für tägliche Aufgaben nutzen, sofern die Failover-Kapazität berücksichtigt wird.
Hier hat VMware die zugrundliegenden Algorithmen erweitert und die zugehörigen GUI-Dialoge vereinfacht. So erleichtert der Dialog zur Cluster-Konfiguration im Bereich „vSphere Availability” jetzt unter dem Link/Untermenü „Admission Control“ sämtliche Einstellungen zur Failover-Kapazität. Diese untergliedern sich nun übersichtlich in die drei Sektionen „Host failures cluster tolerates”, „Define host failover capacity by” und „Performance degradation VMs tolerate”. Die Default-Einstellung bei „Define host failover capacity by” ist „Cluster resource percentage”.
Optional stehen im entsprechenden Listenmenü „Disabled”, „Slot-Policy” oder „Dedicated Failover Host” zur Verfügung, während die erste und dritte Einstellungen lediglich einen numerischen Wert erfordert, wie die Anzahl der Hosts im ersten Fall oder der prozentuale Wert im dritten Fall. Die führt zum von der Vorgängerversionen bekannten Verhalten von Admission Control.
Allerdings wird der Wert für „Define host failover capacity by” jetzt automatisch errechnet, was ein altbekanntes Problem löst: Hatte man nämlich „vor“ vSphere 6.5 den 2-Node-Cluster um einen dritten Host erweitert, dabei aber vergessen, die Prozentregel zu ändern (zum Beispiel 50 Prozent), führte dies zu einer Verschwendung von Ressourcen. In vSphere 6.5 hingegen wird die hierzu benötigte Failover-Kapazität automatisch errechnet.
VM resource reduction event threshold
Neu hingegen ist die Admission-Control-Policy „Performance degradation VMs tolerate”. Diese Erweiterung basiert auf einem bereits im vergangenen Jahr unter Mitwirkung von Duncan Epping (Chief Technologist - Storage und Availability bei VMware und Autor des HA Deepdive) veröffentlichen Flings namens „vm resource and availability service“. Es ermöglicht im Rahmen der Planung der Failover-Kapazität eine Art „Was-wäre-wenn-Analyse“ in Bezug auf etwaige eintretende Host-Ausfälle. Das Feature simuliert den Ausfall von einem oder mehreren Hosts im Cluster, um herausfinden, ...
- welche VMs sich sicher auf anderen Hosts neu starten lassen
- welche VMs nicht sicher auf anderen Hosts neu gestartet werden können
- welche VMs nach dem Neustart auf einem anderen Host mit reduzierter Performance laufen.
Die Einstellung erlaubt Ihnen das Angeben eines Performance-Verlustes, den Administratoren beim Neustarten von VMs auf einem anderen Host im Fehlerfall zu akzeptieren bereit ist. Der Default-Wert ist 100 Prozent. Sie können aber auch 30 Prozent oder 0 Prozent einstellen. Haben sie zum Beispiel in einem 3-Node-Cluster mit 96 GB RAM (3x32GB) bei „Host failures cluster tolerates“ eine „1“ eingetragen, konsumieren alle laufenden VM aktuell 70 Gigabyte RAM und der Wert bei “ Performance degradation VMs tolerate” steht auf 0 Prozent, generiert ESXi eine Warnung, dass die Failover-Kapazität nicht ausreichet.
Warum dies so ist, lässt sich leicht nachvollziehen: Beim Ausfall „eines Hosts” wären im Cluster noch 64 GB RAM verfügbar (96GB -32 GB). Es werden aber 70 GB für laufenden VMs benötigt, wenn diese auf den verbleibenden 2 Hosts neu gestartet werden, weil per Definition (0 Prozent) keine Performance-Verluste in Kauf genommen werden sollen. Die Konsequenz ist, dass sich die verfügbare Failover-Kapazität erhöhen muss, wenn keine Performance-Einbußen im Fehlerfall hinnehmbar wären.
.")
Orchestrated VM Restart
Neu in der HA-Implementation ist auch ein Feature namens „Orchestrated VM Restart“. Es erlaubt in Version 6.5 nicht nur, VMs nach einem Ausfall oder bevor ein Server zur Wartung in den Maintenance-Mode genommen wird, auf einem anderen Host neu starten, sondern auch deren Start-Reihenfolge durch relativ komplexe Regeln zu steuern.
Mit „Orchestrated VM Restart“ können Administratoren „Ketten“ voneinander abhängiger virtueller Maschinen oder Gruppen solcher VMs festlegen und dann die Reihenfolge bestimmen, in der die einzelnen VMs neu gestartet werden. Sie können sogar einstellen, dass ausgewählte VMs mit dem Booten warten, bis der VM sämtliche von ihr durch andere VMs bereitgestellte Dienste tatsächlich zur Verfügung stehen.
In der bisherigen HA-Implementation (bis vSphere 6) gab es hingegen nur die „VM Restart Priority“, die Sie mehr oder weniger prophylaktisch auf „high“, „medium“ oder „low“ setzen konnten. Bei vSphere 6.5 kommen hingegen noch die Optionen „Lowest“ und „Highest“ hinzu. Die Einstellungen finden sich im Dialog „Failures und Responses“, in dem das Verhalten von vSphere HA in Bezug auf bestimmte Fehlerszenarien einstellbar ist, die vSphere-HA erkennen und „behandeln“ kann.
Hier ist der Schutz vor Host-Ausfällen das bei weitem wichtigste Szenario und entspricht der eigentlich HA-Implementation auf Basis von Fault Domain Manager (FDM). VMware vSphere kann optional aber auch Ausfälle von VMs, Applikationen und Storage-Devices erkennen. Mit der VM-Restart-Priority stellen Sie dann ein, welche VMs bei einem Host-Ausfall bevorzugt neu gestartet werden.

Das neue Feature „Orchestrated VM Restart“ konfigurieren Sie dagegen nicht bei “Failures and Responses”, sondern bei „VM Overrides“ in den allgemeinen Cluster-Setting. Mit „Add“ und einem Klick auf das grüne Plus-Symbol lassen sich dann einzelne VMs hinzufügen und mit individuellen Cluster-Einstellungen versehen, welche die auf HA-Cluster-Level konfigurierten Voreinstellungen überschreiben. Eine der hier anpassbaren Einstellungen ist zum Beispiel die erwähnte „VM restart priority“, die Sie an dieser Stelle VM-spezifisch einrichten können, wenn dem Dialog mehrere VMs hinzugefügt werden.
Direkt darunter finden sich drei in vSphere 6.5 neue Einträge „Start next priority VMs when“, „Additional delay“ und „or after timeout occours at“. Mit „Start next priority VMs when“ können Admins etwa durch Auswahl eines der Einträge „Ressource Allocated“, „Powered On“ „Guest Heartbeat dedected“ oder „App Heartbeats detected“ einstellen, ”wodurch” oder “durch was” der Start der nächsten Priority-Gruppe getriggert wird. Dies erlaubt ein granulares Steuern, wann die jeweils nächst höher priorisierte VM/VM-Gruppe startet. Die beiden letztgenannten Optionen setzen allerdings die VMware Tools voraus.

Ist die Start-Priorität an sich festgelegt, lässt sich unter „Additional Boot-Delay“ bei Bedarf einstellen, wie lange HA auf den Start des nächsten Batch wartet. Unter „resources allocated” versteht VMware das pure Scheduling des Batch-Vorgangs selbst, während „Powered On” das Vervollständigen des Power-On-Events als Trigger verwendet oder die Guest- beziehungsweise App-Heartbeat-Erkennung nach dem vollständigen Start der VM samt VMware-Tools und/oder der Anwendung.
Letzteres setzt voraus, dass App-HA aktiviert ist, was wiederum eine „App-HA-aware“ Applikation benötigt, während „VM-Monitoring“ (Guest-HA) nur das Aktivieren der Funktion in den HA-Settings braucht. Allerdings benötigen beide Funktionen die VMware-Tools für das Austauschen von Guest- beziehungsweise App-Heartbeats zwischen VM und Host.
Proactive HA
Ein weiteres neues Feature in vSphere 6.5 ist „Proactive HA“. Diese Erweiterung für High Availability kann Daten über den Zustand der Server-Hardware (System-Health) verwenden, um VMs via „vMotion“ auf einen anderen Host zu verlagern, noch „bevor“ der betreffende Cluster-Knoten ausfällt.

Auf diese Weise lassen sich Server mit aktuell problematischen Health-Indikatoren per Default in einen Quarantäne-Status versetzen. Optional können Sie im Zusammenhang mit Proactive-HA den Maintenance-Modus antriggern. Proactive HA ist also streng genommen gar kein HA-Feature, sondern eher eine DRS-Funktion, da ja die VM ja gar nicht ausfällt, sondern gegebenenfalls rechtzeitig per vMotion verschoben wird.
Wir erläutern Proactive HA zusammen mit dem ebenfalls neuen Feature „Predictive DRS“ im nächsten Teil dieser Reihe.
Artikelfiles und Artikellinks
(ID:44566507)
:quality(80)/p7i.vogel.de/wcms/64/6b/646b6d3886e625484482cb2ad1d2df30/0131318698v1.jpeg "Sathish Balakrishnan, VP und General Manager für Ansible, stellt auf dem „Red Hat Summit 2026“ Neuerungen für die Automatisierungsplattform vor. (Bild: Red Hat / Youtube)")
:quality(80)/p7i.vogel.de/wcms/7e/46/7e46ef019f25112af969a32bfb822eba/0126556157v2.jpeg "Hock Tan sei ein guter Geschäftsmann, sagt IDC-Analyst Jevin Jensen. Hier eröffnet er die Broadcom-Konferenz „VMware Explore 2025“. (Bild: uo/Vogel IT-Medien GmbH)")