
:quality(80)/p7i.vogel.de/wcms/f9/e6/f9e6d7178831f3a939f6cb722e21007f/0132594477v1.jpeg "Redundanz kann ein Sicherheitsgefühl vermitteln, während ungeprüfte Infrastruktur und Notfallprozesse sowie physische und digitale Angriffsrisiken diesen Schein signifikant bedrohen. (Bild: Daniel Schrader / GPT-Image 2 / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/20/a1/20a1347bae821ee294285a2408de3cdb/0132508336v1.jpeg "Der Betreiber setzt bei Rechenzentren auf Ökostrom und Daten in Deutschland. (Bild: Pfalzkom)")
:quality(80)/p7i.vogel.de/wcms/06/50/06506387ede0e72e8d404494a3b9f2b1/0132511022v1.jpeg "KI-Infrastruktur und Rechenzentrumssystems treiben laut Gartner das weltweite IT-Ausgabenwachstum 2026 maßgeblich an. (Bild: © jamesteohart - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/8b/ae/8baee103debba73f2362593fc17d79fc/0132543354v1.jpeg "PUE zeigt Effizienz. Intelligente Laststeuerung entscheidet darüber, wie viel Rechenleistung ein Standort aus seiner verfügbaren Energie- und Netzkapazität herausholt, so Torge Lahrsen. (Bild: Daniel Schrader / GPT Image 2 / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/44/3a/443a4cb166a005757c21dd48a5ae8a26/0132505426v1.jpeg "CPU, GPU, Netzwerk und Software stammen aus dem AMD-Portfolio. Gemeinsam mit Supermicro entsteht eine durchgängige Infrastruktur für KI-Training und Inferenz. (Bild: Gemini / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/e8/d4/e8d462ed9972be2b8464c790cce263c0/0132429621v1.jpeg "Die Integration der KI-gestützten Designexploration von Precision Innovations soll die Silizium-Chip-Entwicklung beschleunigen, so Siemens. (Bild: Siemens)")
:quality(80)/p7i.vogel.de/wcms/37/0a/370aa88021e97f80526e1d07f8a64ca9/0132435873v1.jpeg "Die „ND MI455X v7“-Serie basiert auf AMDs Rackscale-Design und soll Reasoning- und Suchanwendungen sowie KI-Agenten in Azure beschleunigen. (Bild: Midjourney / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/0b/0e/0b0ef1fc1c379ab914c58f63a1ea58be/0132441193v1.jpeg "Storage-Schichten, geo-verteilte Datenhaltung und offene Standards sind die Grundlage für resiliente und souveräne Infrastrukturen. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/67/c3/67c399c0d42006c206b19ca13a408732/0132302716v1.jpeg "AI Restacking integriert Künstliche Intelligenz in alle Ebenen der Unternehmensarchitektur. Geschäftsprozesse, Daten, Anwendungen und Technologien bilden dabei ein vernetztes System, das kontinuierlich aus Daten und Feedback lernt. (Bild: © BalanceFormCreative - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/73/8d/738d892859c9bf552bffeaee476c1bc3/0132416407v1.jpeg "Die Architektur soll KI-Inferenz, Container und virtuelle Maschinen an dezentralen Standorten sichern. (Bild: © Starmarpro - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/bb/84/bb848b79900a103b8aaed3207f1f1055/0132159005v1.jpeg "KI verändert die Wirtschaftlichkeit von Cloud-Infrastrukturen grundlegend. Wer Ressourcen weiterhin statisch bereitstellt, zahlt oft deutlich mehr als technisch erforderlich wäre. (Bild: © Zamrznuti tonovi - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/be/a9/bea9813088d28bae7b19799a194fe99c/0131951229v1.jpeg "Ewe hat seine Java-Umgebung über mehr als 100 Anwendungen und Zehntausende Desktop-Arbeitsplätze standardisiert. Nach Angaben des Unternehmens sanken dadurch die Java-Lizenzkosten um 60 Prozent. (Bild: © RomanR - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/1c/2e/1c2e0effc700eddefcf2264786aef800/0131879187v1.jpeg "Siemens erweitert sein Portfolio für industrielle KI bei der Verarbeitung von Produktionsdaten und bei der Automatisierung von Engineering-Prozessen. (Bild: Midjourney / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/95/a7/95a74d5f20e7e05ab33efde3fdfb1008/0132474712v3.jpeg "Auf der \"ISC High Performance 2026\" präsentierten zahlreiche Hersteller neue Quantencomputer sowie Software und Integrationslösungen für hybride HPC-Umgebungen. (Bild: Alice&Bob)")
:quality(80)/p7i.vogel.de/wcms/63/38/63389b116419fdfba92da2a91ad4c4d2/0132481063v1.jpeg "Fehlende Rechenkapazitäten, geringe Investitionen und internationale Abhängigkeiten bremsen den Aufbau einer europäischen Quantenindustrie. (Bild: Midjourney / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/99/2b/992bf8039e0c0a2818d7c01508cc2fd5/0132147095v1.jpeg "Stephan Reitzenstein vor der Probenkammer der Elektronenstrahl-Lithographie-Anlage: Diese Anlage stellt die hochpräzise Nanostrukturen für skalierbare Quantenlichtquellen her. (Bild: Felix Noak)")
:quality(80)/p7i.vogel.de/wcms/d0/75/d075ceeb4de4543fd6446dd4b26825d2/0131796600v2.jpeg "Am 21. Mai 2026 hat Globa lFoundries den Geschäftszweig „Quantum Technology Solutions“ ins Leben gerufen, der zur Skalierung der Fertigungskapazitäten gedacht ist. Der Geschäftsbereich startet mit Kundenverträgen und einer Pipeline von Quanteninnovatoren, die darauf ausgerichtet sind, auf seiner Plattform zu skalieren, so Silicon Saxony. (Bild: frei lizenziert: Gerhard Altmann)")
:quality(80)/p7i.vogel.de/wcms/a9/a3/a9a38515d76d5d2bdbf552020689dd4c/0132133445v1.jpeg "Veraltete IT-Strukturen, steigende Sicherheitsanforderungen und moderne Workloads: Alles Gründe dafür, die Infrastruktur schrittweise zu modernisieren. Aber wie soll das gelingen, ohne den laufenden Betrieb zu gefährden? (Bild: © Chainarong - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/01/1e/011eecedd1890f96971d8c6334e59403/0131873319v2.jpeg "Das Bild visualisiert einen Zufallszahlengenerator, der auf Quantenfluktuationen beruht (Bild: Fraunhofer IPMS/KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/29/33/2933cd5e834f8070b6c6777334e0aa0e/0131690146v1.jpeg "Wie Unternehmen mit ausgealterten Daten und IT-Hardware ümgehen, ist auch und nicht zuletzt eine Frage der Sicherheit. (Bild: © VladaToday - stock.adobe.com / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/ab/65/ab65db7e99df89b1b486f75c13496180/0132419758v1.jpeg "Rechenzentrum ist nicht gleich Cloud. Über die Unterschiede zwischen Colocation und Cloud-Diensten und weshalb der Zugriff auf Daten wichtiger ist als der Standort der Infrastruktur. (Bild: Midjourney / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/de/01/de011e022cf7a4457aa686dfe2f20755/0132592633v1.jpeg "Blick auf's Kraftwerk Staudinger 2019: Hier plant Uniper die Entwicklung eines Rechenzentrumscampus mit Energieinfrastruktur. (Bild: Kraftwerk Staudinger - power plant Staudinger / Alban.py / CC BY-SA 2.0 / flickr.com)")
:quality(80)/p7i.vogel.de/wcms/47/67/47674acc2bfaf7b633e6a27e5796a056/0132591049v1.jpeg "Das Rechenzentrum in Ohio entsteht nicht im Eigentum von OpenAI. Der Konzern übernimmt vor allem die Rolle des langfristigen Mieters und Koordinators. (Bild: Midjourney / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/dd/3e/dd3e2627864aea6931a85a604ecb9048/0132529570v1.jpeg "Gießen von oben: Im Industriegebiet „Katzenfeld“ soll ein Rechenzentrum entstehen. Was bislang bekannt ist. (Bild: THM Gießen / atxcowboy / CC BY-SA 2.0 / flickr.com)")
:quality(80)/p7i.vogel.de/wcms/48/fa/48fae955ace458bfeb45fb69c5f1cf83/0132525775v1.jpeg "Helmut Kohl spricht sich für einen stärker dezentralen Ausbau der Rechenzentrumslandschaft aus. (Bild: Midjourney / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/f3/da/f3dacd38e5834ae3f3c9d0a4bc9664d3/0113348475.jpeg "Das vom Umweltbundesamt beauftragte Projekt „Public Energy Efficiency Register of Data Centres “ (PeerDC), ist nach Einschätzung der Beteiligten Marina Köhn (UBA), Peter Radgen (IER Uni Stuttgart) und Felix Behrens (Öko-Institut e.V.) ein Erfolg auf ganzer Linie. Das sah DataCenter-Chefredakteurin Ulrike Ostler nach dem DataCenter-Diaries Podcast #16 nicht ganz so rosa. (Bild: sdecoret - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/90/f5/90f56ec6cb3ddbdabca2162fd5477836/0113078524.jpeg "(Bild: Vogel IT-Medien GmbH)")
:quality(80)/p7i.vogel.de/wcms/0f/09/0f097990002b7600075e43c92af4a3fd/0110524571.jpeg "(Bild: frei lizenziert/Krystsina Radzewich)")
:quality(80)/p7i.vogel.de/wcms/66/ae/66ae9e32738784b57e2ad8c1a4b0986f/0109756744.jpeg "Eines der in Deutschland befindlichen NTT-Datacenter - in Hattersheim - und das PeerDC-Logo. (Bild: NTT Global Data Centers )")
:quality(80)/p7i.vogel.de/wcms/b6/2f/b62f5450fa983d6fba21ec3b64a51be3/0132542976v1.jpeg "Wenn man neben dem täglichen Betrieb die Lieferketten von Komponenten und die Bauaktivitäten misst, erscheint der Emissionsbeitrag von Rechenzentren in einem ganz anderen Licht, so Alliance Research. (Bild: Daniel Schrader / GPT Image 2 / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/ee/3f/ee3f063b82737f0369c09ba7854587b5/0127234708v1.jpeg "Das sind die Gewinner der IT-Awards 2025! (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/f1/f0/f1f007a4518fa65d3cb0ea5ca465142a/0121300054v3.jpeg "Strahlende Gesichter bei allen, die die Preise des 10. DataCenter-Insider Award am gestrigen 17. Oktober abholen durften - in den Kategorien: Schnelles Interconnect, Infrastruktur der Resilienz, Coole Kühlung, HPC- und KI-Hardware, Grünes Co-Location und Cloud-native Plattformen. (Bild: Manuel Emme Fotografie)")
:quality(80)/p7i.vogel.de/wcms/a8/28/a828f76369267628d833a12c26dd6579/0121131534v3.jpeg "DataCenter-Insider verleiht heute die IT-Awards 2024 in sechs Kategorien. (Bild: Vogel IT-Medien)")
Übersicht KI- und ML-Stacks, Teil 1 KI-Engines im Bündel mit Hardware
Künstliche Intelligenz (KI) „fällt nicht vom Himmel“. Leistungsstarke KI-Lösungen entstehen auf der Basis gut abgestimmter KI- und Machine Learning Stacks. Davon gibt es zum Glück einige. Etablierte Software-Entwicklungshäuser sind in Sachen KI und Machine Learning (ML) mittlerweile fest im Sattel. Inzwischen wollen andere Unternehmen auch mit ins Boot.
Anbieter zum Thema
:fill(fff,0)/p7i.vogel.de/companies/68/2d/682dd583dcc4c/fsas-afc-horizontal-2-positive-rgb-nov24.png "fsas-afc-horizontal-2-positive-rgb-nov24 (Fsas)")
:fill(fff,0)/p7i.vogel.de/companies/65/65/6565ddb7b8418/dcg-wort-bild-marke-dark-rgb.jpeg "dcg-wort-bild-marke-dark-rgb (DC-Datacenter-Group GmbH)")
Künstliche Intelligenz gilt als ein Oberbegriff für lernfähige Systeme und deckt Maschinelles Lernen (ML) eigentlich mit ab. Der Begriff KI findet dann Anwendung, wann immer von lernenden Anwendungen die Rede ist – auch Algorithmen des Deep Learnings sind hiermit abgedeckt. Im Gegensatz dazu stellt ML die autarken oder semi-autarken Handlungsfähigkeiten cyber-physischer Systeme in den Vordergrund, welche hierzu die Analyse von Datenströmen aus Sensorik in nahezu Echtzeit meistern müssen.

Begrifflichkeiten jetzt aber beiseite: Der KI/ML-Goldrausch ist in vollem Gange. IDC-Analysten zufolge soll der weltweite Markt für KI/ML-Lösungen im laufenden Jahr satte 35,8 Milliarden US-Dollar erreichen und sich damit gegenüber dem Vorjahr mit 44 Prozent Wachstum nahezu verdoppeln.
Das deutsche Bruttoinlandsprodukt (BIP) könnte sich dank KI bis zum Jahr 2030 um insgesamt 11,3 Prozent vergrößern, schätzt PwC. Dieses Wachstum entspricht einer Wertschöpfung von rund 430 Milliarden Euro, also knapp über der aktuellen Gesamtwirtschaftsleistung von Ländern wie Österreich und Norwegen.
Sehen, Hören, Handeln
Unternehmen erhoffen sich von KI/ML-Algorithmen zur Auswertung von Big Data einzigartige Wettbewerbsvorteile: mehr Customer Intelligence, niedrigere Kosten dank prädiktiver Instandhaltung, geringere Betriebsrisiken durch Betrugsprävention und Früherkennung von Cyber-Angriffen. Den Anwendungsmöglichkeiten sind praktisch keine Grenzen gesetzt, sofern sich das Vorhandensein hochwertiger Datenquellen gewährleisten lässt.
Doch was nützt KI als ein Alleinstellungsmerkmal, wenn alle Akteure über dieselben Algorithmen verfügen? Nicht viel. Erst fortgeschrittene KI-Stacks schaffen die Grundlagen, um den Lernfähigkeiten der eigenen Anwendungen die so begehrte Exklusivität zuteilwerden zu lassen.
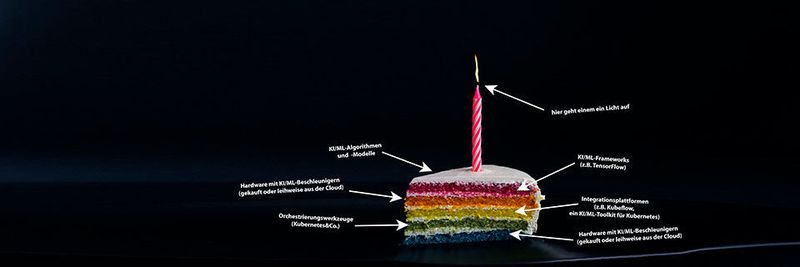
Ein KI-Stack setzt sich wie eine traditionelle Schichttorte aus mehreren Ebenen zusammen. Idealerweise sollten diese ineinander „greifen“ und beim Schneiden und Servieren (sprich: beim Orchestrieren) gut zusammenhalten. Die unterste Ebene des Stacks bildet eine KI/ML-optimierte Hardware (siehe den Abschnitt „Aufgebohrt: KI-Optimierte Hardware“ weiter unten).
Auf diesem Infrastrukturfundament setzen dann die Orchestrierungswerkzeuge auf (zum Beispiel Kubernetes). Eine weitere Softwareschicht, die dann wiederum darauf aufbaut, zeichnet für das Management der Orchestrierungswerkzeuge und somit auch die Portabilität des Softwarestacks zwischen verschiedenen Laufzeitumgebungen verantwortlich (mehr zu diesen Aspekten eines Stacks im Abschnitt „Eingespielt: Orchestrierungs-Tools für KI/ML-Workloads“ im zweiten Teil dieser Folge).
Darauf setzt dann das eigentliche KI/ML-Framework auf. Dieses lässt sich gegebenenfalls um externe Dienste, Bibliotheken und sonstige anwendungsspezifische Erweiterungen ergänzen, zum Beispiel im Bereich der Bilderkennung oder Sprachanalyse. Erst oberhalb dieser Schicht entstehen die eigentlichen KI/ML-Modelle und -Visualisierungen. Aus welchen Bestandteilen sich ein bestimmter KI/ML-Stack im Einzelnen zusammensetzt, hängt also im Endeffekt von den avisierten Anwendungsszenarien ab.
Aufgebohrt: KI-optimierte Hardware
KI-Algorithmen wie künstliche Neuronale Netze für maschinelles Lernen müssen in der Inferenzphase die anfallenden Datenströme möglichst echtzeitnah verarbeiten, um zu gewährleisten, dass cyber-physische Systeme auch in Situationen mit hoher Ungewissheit und in einem stark individualisierten Kontext autark handeln können.
Neuronale Netze durchlaufen üblicherweise die hierzu erforderliche Trainingsphase, welche die Verarbeitung massiver Big-Data-Bestände voraussetzt, in verteilten Anwendungsarchitekturen in einem voll ausgewachsenen Rechenzentrum. Erst die Inferenzphase kann dann auf dem betreffenden cyberphysischen Edge-System stattfinden, etwa in einer autonomen Drohne.
Im Gegensatz dazu können sich diejenigen lernenden Algorithmen, die rein historische Daten verarbeiten, sich zwar damit generell mehr Zeit lassen, doch für die Entwickler gestaltet sich das Ganze wohl kaum einfacher. Denn in der ursprünglichen Lernphase geht es vorrangig darum, zuvor ungekannte Zusammenhänge in massiven Datenmengen aufzudecken, statt „nur“ vorgegebenen Denkmustern durch iterative Verbesserungen zu folgen. Diese Herangehensweise ist unter dem Namen Deep Learning bekannt.
Konventionelle CPUs sind mit datenlastigen KI-Workloads nach wie vor überfordert. Sie haben ja auch mittlerweile kaum Spielraum, an Leistung zuzulegen, weil sich das Mooresche Gesetz unweigerlich seinem Ende nähert. Der Aufbau eines KI/ML-Stacks setzt daher zwingend geeignete Hardware voraus. Es fragt sich nur, welche.
Eingebettet den Datenhunger sättigen
Bisher stehen Entwicklern von KI/ML-Algorithmen GPUs (Graphic Processing Units) von Nvidia, FPGAs (Field Programmable Gate Arrays) und ASICs wie die TPU (Tensor Processing Units) von Google zur Verfügung.
:quality(80)/images.vogel.de/vogelonline/bdb/1583500/1583544/original.jpg "Der rote Faden: Abgebildet ist das neuromorphe Rechnersystem aus Heidelberg „Brainscale S“, ausgelegt für 20 Wafer-Module, 3.932.160 Neuronen und 880.803.840 Synapsen . (Universität Heidelberg / CC BY-ND 4.0)")
Hirn im Computer
Was ist neuromorphes Computing?- Was sind neuromorphe Chips?
Hirn im Computer
Was ist neuromorphes Computing?- Was sind neuromorphe Chips?
:quality(80)/images.vogel.de/vogelonline/bdb/1359500/1359540/original.jpg "Wo Hardware zählt: Im Konzeptauto Audi AI, einem Edge-Rechenzentrum auf Achse, werkelt die „Drive PX“-Plattform von Nvidia für autonome Fahrzeuge. (Audi)")
IPUs, DPUs, DLUs und mehr
Wo Hardware zählt: KI mit System
Diese und andere KI/ML-optimierte Chip-Architekturen sollen über das Ende des Mooreschen Gesetzes hinaus eine Brücke in die Zukunft schlagen. Welches Gelände sich den KI/ML-Entwicklern auf dem anderen Ende dieser Brücke erschließt, weiß bisher so genau noch keiner. Laut den Analysten von Gartner dürften unter anderem Quanten-Computer und neuromorphische Chips die Nachfolge heutiger Hardwarebeschleuniger und domainspezifischer Prozessoren antreten.
:quality(80)/images.vogel.de/vogelonline/bdb/1495200/1495243/original.jpg "Durchblick: Das IBM Q Lab. (IBM)")
Probleme, Lösungen, Mathe und Materialien von Quantencomputern
Quanten-Gate-Computer versus Annealer
Zu den guten Nachrichten zählt der Umstand, dass Unternehmen KI-Stacks aufbauen können, ohne sich erst mit spezialisierter Hardware eindecken zu müssen. Die führenden Cloud-Dienstleister bieten Hardware als ein Service aus der Wolke an. So vermietet beispielsweise Google die zweite und dritte Generation der TPU-Beschleuniger für KI-Modelle auf der Basis von Matrizenberechnungen, gebündelt zu je tausend Stück, über die Google Cloud Platform. Als Vorzeigekunden nennt Google unter anderem die Metro-Gruppe und die Siemens AG.

Der internationale Spezialist für den Großhandel- und Lebensmitteldirektvertrieb aus Düsseldorf hat seine 100 separaten Buchhaltungssysteme auf SAP-HANA in der Google-Cloud konsolidiert, enthüllt Timo Salzsieder, CIO/CSO der Unternehmensgruppe, bekannt. So könne der Metro-Konzern fortgeschrittene Big-Data-Analysetechniken und KI u. a. zur Optimierung der eigenen Versorgungsketten nutzen.
:quality(80)/images.vogel.de/vogelonline/bdb/1432600/1432674/original.jpg "Google bringt einen eigenen KI-ASIC sowie ein Referenzdesign für das Edge-Computing heraus. (Google)")
Der KI-Beschleuniger für den Einsatz in LG-Fabriken
Google bringt TPU für Inferenz-Rechner heraus
:quality(80)/images.vogel.de/vogelonline/bdb/1395600/1395643/original.jpg "Das TPU-Motherboard zeigt eine direkte Flüssigkühlung: Vier Chips auf jeder Karte und Kühlmittel, das über jeden ASIC läuft und Hitze an die Kupferkühlplatten abgibt. (Google)")
Die Luft reicht nicht
Googles Machine-Learning-Chip braucht Flüssigkeit
Der Lebensmittelkonzern lässt seine Daten in die serverlose PaaS-Plattform BigQuery von Google via die Datalab-Infrastruktur einfließen. Hier entstehen unter Verwendung des quelloffenen KI-Frameworks „Tensorflow“ und unter aktiver Mitwirkung der KI-Spezialistin Freiheit.com Technologies GmbH aus Hamburg die eigentlichen ML-Modelle, enthüllt Stefan Richter, Founder and Head of Engineering bei freiheit.com. Die so gewonnenen Erkenntnisse ließen sich dann mithilfe von Google Data Studio in verschiedenen Unternehmensbereichen visualisieren. So lernt die Metro-Gruppe ihre Kunden in Echtzeit kennen.
Branchenspezifische Full-Stack-Fertiggerichte servieren — oder lieber doch selbst backen?

Im Grunde genommen stehen den Unternehmen in Bezug auf die Wahl eines KI-Stacks mehrere diametral unterschiedliche Ansätze offen. Zum einen gibt es branchenspezifische Full-Stack-Umgebungen wie die Drive-Plattform für autonome Fahrzeuge von Nvidia. Das Unternehmen bietet seinen Partnern unter anderem Referenzdesigns, eine Entwicklungsumgebung, eine Simulationsplattform und ein künstliches neuronales Netzwerk zum Trainieren von ML-Fähigkeiten im Bereich der audiovisuellen Wahrnehmung. Nvidia ging bereits strategische Partnerschaften unter anderem mit Audi, Mercedes-Benz und VW ein.
Wer eine solche branchenspezifische KI-Entwicklungsplattform nicht benötigt, kann einen eigenen KI/ML-Stack aus quelloffenen Frameworks wahlweise auf eigener Hardware und/oder — wie die Metro-Gruppe — in der Cloud zusammenstellen (siehe dazu den zweiten Teil des Berichtes „KI/ML-Stacks, Teil 2: die (künstliche) Framework-Intelligenz“).
Viele der beliebtesten quelloffenen Frameworks für Maschinelles Lernen (ML), allen voran Tensorflow, sind bei den großen Cloud-Anbietern als vollständig „gemanagte“ Services verfügbar. Dies senkt die Verwaltungskosten, fördert jedoch die Abhängigkeit von den proprietären Lösungen und den Kompetenzen des jeweiligen Dienstleisters.
Cloud-Dienste trumpfen wiederum mit der Fähigkeit, ihren Nutzern die benötigten Hardwarebeschleuniger bedarfsgerecht und kostengünstig zur Verfügung zu stellen. Amazons KI-Dienst Elastic Inference unterstützt beispielsweise den Einsatz von GPU-Beschleunigern für KI/ML-Workloads des Deep Learnings in der Cloud.
McKinsey Global Institute (MGI) schätzt das Wachstumspotenzial der deutschen Wirtschaft durch KI-Technologien bis zum Jahre 2030 (jährlich 1,3 Prozent) auf etwa 16,7 Prozent. Um dieses Ziel zu erreichen, müssten allerdings 70 Prozent aller Unternehmen bis zum Jahr 2030 KI-Lösungen einsetzen, vor allem in den Bereichen automatische Bilderkennung, natürliche Sprache, virtuelle Assistenten, roboterbasierte Prozessautomatisierung und fortgeschrittenes maschinelles Lernen.
Fazit des Autorenduos
Die Wahl des KI/ML-Stacks ist keine leichte Entscheidung. Um die steile Lernkurve zu überwinden, entscheiden sich einige Firmen für strategische Partnerschaften, andere wählen wiederum den Weg der kleine Schritte, indem sie eine KI/ML-Lösung nach einem eigenen Rezept aus öffentlich verfügbaren KI/ML-Frameworks „backen“ und hierbei auf die Kompetenzen von Infrastrukturdienstleistern und KI/ML-Entwicklungsschmieden zurückgreifen. Wie dem auch sei: An der intelligenten Auswertung von Big Data kommt keiner mehr vorbei.
* Das Autoren-Duo Filipe Pereira Martins und Anna Kobylinska arbeitet für die Soft1T S.a r.l. Beratungsgesellschaft mbH, McKinley Denali Inc. (USA).
(ID:46126732)
:quality(80)/p7i.vogel.de/wcms/7f/39/7f3904c8e34848303d65dcb8fa84bef0/0126326548v1.jpeg "Im Bild: Die Kühlanlagen auf dem Dach des „Modular Data Centre“, in dem „Jupiter“untergebracht ist. Mit mehr als 60 Milliarden Rechenoperationen pro Watt ist Jupiter der effizienteste unter den fünf leistungsfähigsten Superrechnern der Welt. (Bild: Forschungszentrum Jülich/Sascha Kreklau)")
:quality(80)/p7i.vogel.de/wcms/3e/7b/3e7bf017d813331ad40ba2ef91c3bf81/0130092884v2.jpeg "Das Bild zeigt einen Hammerhai, aber selbstredend ist das nicht der, den EuroHPC JU beschafft und das HLRS hostet, nämlich die Hybrid and Advanced Machine Learning Platform for Manufacturing, Engineering, and Research. Die Hardware für den Supercomputer stammt von HPE. (Bild: © hakbak - stock.adobe.com)")