
:quality(80)/p7i.vogel.de/wcms/f9/e6/f9e6d7178831f3a939f6cb722e21007f/0132594477v1.jpeg "Redundanz kann ein Sicherheitsgefühl vermitteln, während ungeprüfte Infrastruktur und Notfallprozesse sowie physische und digitale Angriffsrisiken diesen Schein signifikant bedrohen. (Bild: Daniel Schrader / GPT-Image 2 / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/20/a1/20a1347bae821ee294285a2408de3cdb/0132508336v1.jpeg "Der Betreiber setzt bei Rechenzentren auf Ökostrom und Daten in Deutschland. (Bild: Pfalzkom)")
:quality(80)/p7i.vogel.de/wcms/06/50/06506387ede0e72e8d404494a3b9f2b1/0132511022v1.jpeg "KI-Infrastruktur und Rechenzentrumssystems treiben laut Gartner das weltweite IT-Ausgabenwachstum 2026 maßgeblich an. (Bild: © jamesteohart - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/8b/ae/8baee103debba73f2362593fc17d79fc/0132543354v1.jpeg "PUE zeigt Effizienz. Intelligente Laststeuerung entscheidet darüber, wie viel Rechenleistung ein Standort aus seiner verfügbaren Energie- und Netzkapazität herausholt, so Torge Lahrsen. (Bild: Daniel Schrader / GPT Image 2 / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/44/3a/443a4cb166a005757c21dd48a5ae8a26/0132505426v1.jpeg "CPU, GPU, Netzwerk und Software stammen aus dem AMD-Portfolio. Gemeinsam mit Supermicro entsteht eine durchgängige Infrastruktur für KI-Training und Inferenz. (Bild: Gemini / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/e8/d4/e8d462ed9972be2b8464c790cce263c0/0132429621v1.jpeg "Die Integration der KI-gestützten Designexploration von Precision Innovations soll die Silizium-Chip-Entwicklung beschleunigen, so Siemens. (Bild: Siemens)")
:quality(80)/p7i.vogel.de/wcms/37/0a/370aa88021e97f80526e1d07f8a64ca9/0132435873v1.jpeg "Die „ND MI455X v7“-Serie basiert auf AMDs Rackscale-Design und soll Reasoning- und Suchanwendungen sowie KI-Agenten in Azure beschleunigen. (Bild: Midjourney / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/0b/0e/0b0ef1fc1c379ab914c58f63a1ea58be/0132441193v1.jpeg "Storage-Schichten, geo-verteilte Datenhaltung und offene Standards sind die Grundlage für resiliente und souveräne Infrastrukturen. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/67/c3/67c399c0d42006c206b19ca13a408732/0132302716v1.jpeg "AI Restacking integriert Künstliche Intelligenz in alle Ebenen der Unternehmensarchitektur. Geschäftsprozesse, Daten, Anwendungen und Technologien bilden dabei ein vernetztes System, das kontinuierlich aus Daten und Feedback lernt. (Bild: © BalanceFormCreative - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/73/8d/738d892859c9bf552bffeaee476c1bc3/0132416407v1.jpeg "Die Architektur soll KI-Inferenz, Container und virtuelle Maschinen an dezentralen Standorten sichern. (Bild: © Starmarpro - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/bb/84/bb848b79900a103b8aaed3207f1f1055/0132159005v1.jpeg "KI verändert die Wirtschaftlichkeit von Cloud-Infrastrukturen grundlegend. Wer Ressourcen weiterhin statisch bereitstellt, zahlt oft deutlich mehr als technisch erforderlich wäre. (Bild: © Zamrznuti tonovi - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/be/a9/bea9813088d28bae7b19799a194fe99c/0131951229v1.jpeg "Ewe hat seine Java-Umgebung über mehr als 100 Anwendungen und Zehntausende Desktop-Arbeitsplätze standardisiert. Nach Angaben des Unternehmens sanken dadurch die Java-Lizenzkosten um 60 Prozent. (Bild: © RomanR - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/1c/2e/1c2e0effc700eddefcf2264786aef800/0131879187v1.jpeg "Siemens erweitert sein Portfolio für industrielle KI bei der Verarbeitung von Produktionsdaten und bei der Automatisierung von Engineering-Prozessen. (Bild: Midjourney / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/95/a7/95a74d5f20e7e05ab33efde3fdfb1008/0132474712v3.jpeg "Auf der \"ISC High Performance 2026\" präsentierten zahlreiche Hersteller neue Quantencomputer sowie Software und Integrationslösungen für hybride HPC-Umgebungen. (Bild: Alice&Bob)")
:quality(80)/p7i.vogel.de/wcms/63/38/63389b116419fdfba92da2a91ad4c4d2/0132481063v1.jpeg "Fehlende Rechenkapazitäten, geringe Investitionen und internationale Abhängigkeiten bremsen den Aufbau einer europäischen Quantenindustrie. (Bild: Midjourney / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/99/2b/992bf8039e0c0a2818d7c01508cc2fd5/0132147095v1.jpeg "Stephan Reitzenstein vor der Probenkammer der Elektronenstrahl-Lithographie-Anlage: Diese Anlage stellt die hochpräzise Nanostrukturen für skalierbare Quantenlichtquellen her. (Bild: Felix Noak)")
:quality(80)/p7i.vogel.de/wcms/d0/75/d075ceeb4de4543fd6446dd4b26825d2/0131796600v2.jpeg "Am 21. Mai 2026 hat Globa lFoundries den Geschäftszweig „Quantum Technology Solutions“ ins Leben gerufen, der zur Skalierung der Fertigungskapazitäten gedacht ist. Der Geschäftsbereich startet mit Kundenverträgen und einer Pipeline von Quanteninnovatoren, die darauf ausgerichtet sind, auf seiner Plattform zu skalieren, so Silicon Saxony. (Bild: frei lizenziert: Gerhard Altmann)")
:quality(80)/p7i.vogel.de/wcms/a9/a3/a9a38515d76d5d2bdbf552020689dd4c/0132133445v1.jpeg "Veraltete IT-Strukturen, steigende Sicherheitsanforderungen und moderne Workloads: Alles Gründe dafür, die Infrastruktur schrittweise zu modernisieren. Aber wie soll das gelingen, ohne den laufenden Betrieb zu gefährden? (Bild: © Chainarong - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/01/1e/011eecedd1890f96971d8c6334e59403/0131873319v2.jpeg "Das Bild visualisiert einen Zufallszahlengenerator, der auf Quantenfluktuationen beruht (Bild: Fraunhofer IPMS/KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/29/33/2933cd5e834f8070b6c6777334e0aa0e/0131690146v1.jpeg "Wie Unternehmen mit ausgealterten Daten und IT-Hardware ümgehen, ist auch und nicht zuletzt eine Frage der Sicherheit. (Bild: © VladaToday - stock.adobe.com / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/ab/65/ab65db7e99df89b1b486f75c13496180/0132419758v1.jpeg "Rechenzentrum ist nicht gleich Cloud. Über die Unterschiede zwischen Colocation und Cloud-Diensten und weshalb der Zugriff auf Daten wichtiger ist als der Standort der Infrastruktur. (Bild: Midjourney / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/de/01/de011e022cf7a4457aa686dfe2f20755/0132592633v1.jpeg "Blick auf's Kraftwerk Staudinger 2019: Hier plant Uniper die Entwicklung eines Rechenzentrumscampus mit Energieinfrastruktur. (Bild: Kraftwerk Staudinger - power plant Staudinger / Alban.py / CC BY-SA 2.0 / flickr.com)")
:quality(80)/p7i.vogel.de/wcms/47/67/47674acc2bfaf7b633e6a27e5796a056/0132591049v1.jpeg "Das Rechenzentrum in Ohio entsteht nicht im Eigentum von OpenAI. Der Konzern übernimmt vor allem die Rolle des langfristigen Mieters und Koordinators. (Bild: Midjourney / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/dd/3e/dd3e2627864aea6931a85a604ecb9048/0132529570v1.jpeg "Gießen von oben: Im Industriegebiet „Katzenfeld“ soll ein Rechenzentrum entstehen. Was bislang bekannt ist. (Bild: THM Gießen / atxcowboy / CC BY-SA 2.0 / flickr.com)")
:quality(80)/p7i.vogel.de/wcms/48/fa/48fae955ace458bfeb45fb69c5f1cf83/0132525775v1.jpeg "Helmut Kohl spricht sich für einen stärker dezentralen Ausbau der Rechenzentrumslandschaft aus. (Bild: Midjourney / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/f3/da/f3dacd38e5834ae3f3c9d0a4bc9664d3/0113348475.jpeg "Das vom Umweltbundesamt beauftragte Projekt „Public Energy Efficiency Register of Data Centres “ (PeerDC), ist nach Einschätzung der Beteiligten Marina Köhn (UBA), Peter Radgen (IER Uni Stuttgart) und Felix Behrens (Öko-Institut e.V.) ein Erfolg auf ganzer Linie. Das sah DataCenter-Chefredakteurin Ulrike Ostler nach dem DataCenter-Diaries Podcast #16 nicht ganz so rosa. (Bild: sdecoret - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/90/f5/90f56ec6cb3ddbdabca2162fd5477836/0113078524.jpeg "(Bild: Vogel IT-Medien GmbH)")
:quality(80)/p7i.vogel.de/wcms/0f/09/0f097990002b7600075e43c92af4a3fd/0110524571.jpeg "(Bild: frei lizenziert/Krystsina Radzewich)")
:quality(80)/p7i.vogel.de/wcms/66/ae/66ae9e32738784b57e2ad8c1a4b0986f/0109756744.jpeg "Eines der in Deutschland befindlichen NTT-Datacenter - in Hattersheim - und das PeerDC-Logo. (Bild: NTT Global Data Centers )")
:quality(80)/p7i.vogel.de/wcms/b6/2f/b62f5450fa983d6fba21ec3b64a51be3/0132542976v1.jpeg "Wenn man neben dem täglichen Betrieb die Lieferketten von Komponenten und die Bauaktivitäten misst, erscheint der Emissionsbeitrag von Rechenzentren in einem ganz anderen Licht, so Alliance Research. (Bild: Daniel Schrader / GPT Image 2 / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/ee/3f/ee3f063b82737f0369c09ba7854587b5/0127234708v1.jpeg "Das sind die Gewinner der IT-Awards 2025! (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/f1/f0/f1f007a4518fa65d3cb0ea5ca465142a/0121300054v3.jpeg "Strahlende Gesichter bei allen, die die Preise des 10. DataCenter-Insider Award am gestrigen 17. Oktober abholen durften - in den Kategorien: Schnelles Interconnect, Infrastruktur der Resilienz, Coole Kühlung, HPC- und KI-Hardware, Grünes Co-Location und Cloud-native Plattformen. (Bild: Manuel Emme Fotografie)")
:quality(80)/p7i.vogel.de/wcms/a8/28/a828f76369267628d833a12c26dd6579/0121131534v3.jpeg "DataCenter-Insider verleiht heute die IT-Awards 2024 in sechs Kategorien. (Bild: Vogel IT-Medien)")
Apache Spark für IBM z Systems Schnellere und einfachere Analysen für Mainframe-Daten
Mit der „z/OS-Plattform für Apache Spark“ will IBM Unternehmen und Behörden erleichtern, auf ihre Mainframe-Daten zuzugreifen und diese lokal, ohne Offloads zu analysieren - und das auch noch mit Zeitersparnis.
Anbieter zum Thema
:fill(fff,0)/p7i.vogel.de/companies/64/e4/64e4be0db6ddc/rittal-4c-w.png "rittal-4c-w (Rittal GmbH & Co. KG)")
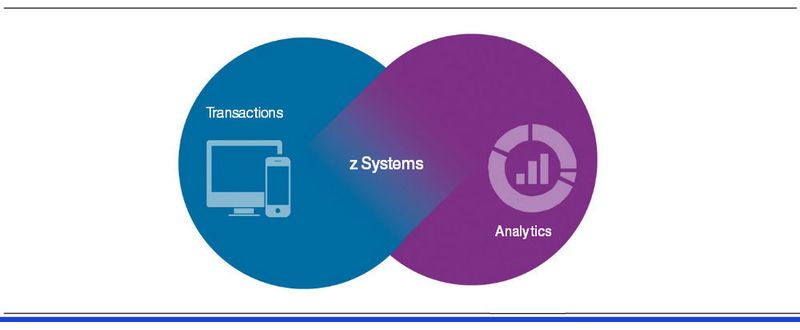
Insgesamt sollen sich durch die z/OS-Plattform für Apache Spark für Datenanalysten sowie Entwickler neue Möglichkeiten ergeben; denn sie können die modernen Open-Source-Analysewerkzeuge für den reichhaltigen Datenbestand auf dem Mainframe einsetzen und dadurch mehr Erkenntnisse in Echtzeit gewinnen. Die Plattform ermöglicht es Spark, einem Open-Source-Analytik-Framework, nativ auf dem z/OS-Betriebssystem laufen zu lassen.
Somit können Experten Daten dort analysieren, wo sie entstehen. Indem die Verbindung zwischen der Analytik-Library und dem zugrundeliegenden Dateisystem entfällt, müssen Daten nicht mehr extrahiert, umgewandelt und geladen werden wie beim bekannten ETL-Verfahren (ETL = Extract, Transform, Load).
Im „kognitiven Zeitalter“, in dem Daten die neue natürliche Ressource darstellen und Computersysteme verstehen, bewerten und lernen können, müssten sich Unternehmen auf veränderte Entwicklungen einstellen und Erkenntnisse aus Informationen zunutze machen, bevor diese irrelevant werden, so IBM. Mit dem neuen Angebot, das auch Akzeleratoren von z-Systems-Geschäftspartnern umfasst, können sich Organisationen Mainframe-Daten und -Ressourcen noch einfacher zunutze machen. Dadurch sind sie imstande, Marktveränderungen als auch individualisierte Kundenbedürfnisse besser zu verstehen und Anpassungen ihrer Marktaktivitäten in Echtzeit sowie mit kürzerer Amortisierungszeit vorzunehmen.

Ein Sprung in die digitale Zukunft
Viele der weltweit größten Banken, Versicherungen sowie Einzelhandels- und Transportunternehmen aber auch Behörden wollen nicht auf Großrechner verzichten. Denn z Systems verarbeiten unternehmenswichtige Daten und Transaktionen und verfügen über die derzeit schnellsten kommerziellen Mikroprozessoren der Branche und die Fähigkeit, Analytik während Transaktionen durchzuführen. Dabei werden Vorhersagemodelle binnen einer Transaktion in zwei Millisekunden oder weniger mit einbezogen.
Diese Organisationen können nun durch Spark diese Ressourcen unter Verwendung von In-Memory-Analytik wirksam einsetzen, ohne Daten vom Großrechner herunterladen zu müssen. Damit sparen sie Zeit und Geld und Risiken werden begrenzt.
Rod Smith, IBM Fellow, Emerging Internet Technologies, erläutert: „Da sich Unternehmen jeder Größe in digitale Organisationen verwandeln, müssen sie sich ein klares Bild von allen vorhandenen Geschäftsdaten machen können. Der Zeitverlust und die Risiken von Data-Offloads können dabei nicht in Kauf genommen werden.“Apache Spark, das jetzt originär auf IBM Plattformen inklusive dem Mainframe betriebsbereit ist, ermögliche Kunden die Durchführung von Analysen bei den Transaktionssystemen, die die wichtigen Daten beherbergen. Gleichzeitig ließen sich kontextbezogene Erkenntnisse von anderen Datenquellen einbinden.

Die IBM z/OS-Plattform für Apache Spark umfasst Open-Source-Ressourcen von Spark, die aus dem „Apache Spark Core“, „Spark SQL“, „Spark Streaming“, der „Machine Learning Library“ (MLlib) und „Graphx“ bestehen, kombiniert mit der branchenweit einzigen Mainframe-basierten Datenabstraktionslösung von Spark. Laut IBM ergebn sich folgende Vorteile:
Optimierte Entwicklung – Entwickler und Datenanalysten können ihr vorhandenes Know-how mit Programmiersprachen wie Scala, Python, R und SQL einsetzen. Dadurch lässt sich die aufzuwendende Zeit für umsetzbare Erkenntnisse reduzieren.
Vereinfachter Datenzugriff – Optimierte Dienste zur Datenabstraktion beheben Komplexität, indem sie mit vertrauten Werkzeugen über Apache Spark-APIs einen nahtlosen Zugriff auf Unternehmensdaten in traditionellen Formaten wie „IMS“, „VSAM“, „DB2 z/OS“, „PDSE“ oder „SMF“ bieten.
In-Place-Datenanalyse – Apache Spark verwendet einen In-Memory-Ansatz zur Verarbeitung von Daten, um schnell Ergebnisse zu erzielen. Die Plattform umfasst Dienste zur Datenabstraktion und -integration, die z/OS-Analytics-Anwendungen zur Nutzung von Standard-Spark-APIs befähigen. Dadurch können Organisationen Daten „vor Ort“ analysieren und mit Offload/ETL verbundene, teure Verarbeitungs- sowie Sicherheitsüberlegungen vermeiden.
Open-Source-Ressourcen – Die Plattform bietet eine Apache Spark-Distribution der Open-Source-In-Memory-Processing-Engines, die für große Datenmengen ausgelegt ist.
Unternehmenspartnerschaften
Um das eigene Angebot zu erweitern arbeitet IBM mit Partnern zusammen: Datafact Z, Rocket-Software und Zementis:
- Datafact Z ist ein neuer IBM-Partner und entwickelt gemeinsam mit dem Unternehmen Spark-Analytik auf der Basis von Spark-SQL und MLlib für Daten und Transaktionen, die auf dem Großrechner verarbeitet werden.
- Rocket-Software und IBM verbindet bereits eine langjährige Zusammenarbeit, die sich nun um z/OS Apache Spark erweitert. Zum Beispiel wird die neue Launchpad-Lösung von Rocket Kunden ermöglichen, die Plattform auszuprobieren und Daten auf z/OS zu verwenden.
- Zementis ergänzt sein Angebot von In-Transaktion-Predictive-Analytik für z/OS mit einer standardbasierten Execution-Engine für Apache Spark. Die Software ermöglicht Nutzern, Vorhersagemodelle anzuwenden und auszuführen. Diese Modelle können sie darin unterstützen, die Bedürfnisse von Endnutzern zu antizipieren, Risiken zu kalkulieren oder Betrugsversuche am Punkt der größten Auswirkungen in Echtzeit zu erfassen, während eine Transaktion verarbeitet wird.
Das IBM-Bekenntnis
Das IBM-Commitment zu Spark stammt aus dem vergangenen Jahr. Dazu gehört, dass mehr als 3.500 Forscher und Entwickler von IBM an zugehörigen Projekten arbeiten. Im Rahmen des Commitments, Open-Source-Technologien für Analytik auf dem Mainframe voranzubringen, hat der Geschäftsbereich z Systems eine neue GitHub-Organisation für Entwickler gegründet, um gemeinsam Tools rund um z/OS auf Spark zu bauen. Zum Beispiel kann eine Kombination aus dem „Projekt Jupyter“ und einer NoSQL-Datenbank eine flexible sowie erweiterbare Datenverarbeitungs- und Analyse-Lösung ermöglichen.
Dieser Ansatz kann helfen, moderne Open-Source-Tools zugänglicher zu machen, indem Entwickler ihre Werkzeuge als auch Sprachen selbst wählen können, neue visuelle Hilfsmittel zur Beobachtung von Analytik-Ergebnissen über unterschiedliche Datenumgebungen hinweg zur Verfügung gestellt werden und damit moderne Datenverarbeitungstechniken sowie -fähigkeiten möglich werden.
Download
Die IBM z/OS-Plattform für Apache Spark steht Entwicklern, die mit z/OS arbeiten, jetzt zum Download bereit.
(ID:43974988)
:quality(80)/p7i.vogel.de/wcms/20/f0/20f0cbbd1d114701185a7e47f8ea2b38/0129915040v1.jpeg "Die Hardware-Vorgaben „Cnode-X“von Vast Data erweitern die GPU-Beschleunigung über Training und Inferenz hinaus auf Vektorsuche, SQL-Analysen und die Orchestrierung containerisierter KI-Modelle. Speicher, Datenbank, Event Broker. Funktionen und KI-Modelle laufen alle nativ auf dem „Vast AI“-Betriebssystem und lassen die Idee einer denkenden Maschine näher rücken. Hardware-Partner sind etwa Supermicro und Cisco. (Bild: Vast Data)")
:quality(80)/p7i.vogel.de/wcms/51/ff/51ff2ae588ea35cea7bfa27bc1128b1c/0129998600v2.jpeg "Mithilfe der Integration von Preciceley- und Mattillion-Tools sollen Kunden beispielsweise fix und Cloud-nativ ETL-Pipelines erstellen können. (Bild: Preciceley)")