
:quality(80)/p7i.vogel.de/wcms/f9/e6/f9e6d7178831f3a939f6cb722e21007f/0132594477v1.jpeg "Redundanz kann ein Sicherheitsgefühl vermitteln, während ungeprüfte Infrastruktur und Notfallprozesse sowie physische und digitale Angriffsrisiken diesen Schein signifikant bedrohen. (Bild: Daniel Schrader / GPT-Image 2 / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/20/a1/20a1347bae821ee294285a2408de3cdb/0132508336v1.jpeg "Der Betreiber setzt bei Rechenzentren auf Ökostrom und Daten in Deutschland. (Bild: Pfalzkom)")
:quality(80)/p7i.vogel.de/wcms/06/50/06506387ede0e72e8d404494a3b9f2b1/0132511022v1.jpeg "KI-Infrastruktur und Rechenzentrumssystems treiben laut Gartner das weltweite IT-Ausgabenwachstum 2026 maßgeblich an. (Bild: © jamesteohart - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/8b/ae/8baee103debba73f2362593fc17d79fc/0132543354v1.jpeg "PUE zeigt Effizienz. Intelligente Laststeuerung entscheidet darüber, wie viel Rechenleistung ein Standort aus seiner verfügbaren Energie- und Netzkapazität herausholt, so Torge Lahrsen. (Bild: Daniel Schrader / GPT Image 2 / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/44/3a/443a4cb166a005757c21dd48a5ae8a26/0132505426v1.jpeg "CPU, GPU, Netzwerk und Software stammen aus dem AMD-Portfolio. Gemeinsam mit Supermicro entsteht eine durchgängige Infrastruktur für KI-Training und Inferenz. (Bild: Gemini / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/e8/d4/e8d462ed9972be2b8464c790cce263c0/0132429621v1.jpeg "Die Integration der KI-gestützten Designexploration von Precision Innovations soll die Silizium-Chip-Entwicklung beschleunigen, so Siemens. (Bild: Siemens)")
:quality(80)/p7i.vogel.de/wcms/37/0a/370aa88021e97f80526e1d07f8a64ca9/0132435873v1.jpeg "Die „ND MI455X v7“-Serie basiert auf AMDs Rackscale-Design und soll Reasoning- und Suchanwendungen sowie KI-Agenten in Azure beschleunigen. (Bild: Midjourney / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/0b/0e/0b0ef1fc1c379ab914c58f63a1ea58be/0132441193v1.jpeg "Storage-Schichten, geo-verteilte Datenhaltung und offene Standards sind die Grundlage für resiliente und souveräne Infrastrukturen. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/67/c3/67c399c0d42006c206b19ca13a408732/0132302716v1.jpeg "AI Restacking integriert Künstliche Intelligenz in alle Ebenen der Unternehmensarchitektur. Geschäftsprozesse, Daten, Anwendungen und Technologien bilden dabei ein vernetztes System, das kontinuierlich aus Daten und Feedback lernt. (Bild: © BalanceFormCreative - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/73/8d/738d892859c9bf552bffeaee476c1bc3/0132416407v1.jpeg "Die Architektur soll KI-Inferenz, Container und virtuelle Maschinen an dezentralen Standorten sichern. (Bild: © Starmarpro - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/bb/84/bb848b79900a103b8aaed3207f1f1055/0132159005v1.jpeg "KI verändert die Wirtschaftlichkeit von Cloud-Infrastrukturen grundlegend. Wer Ressourcen weiterhin statisch bereitstellt, zahlt oft deutlich mehr als technisch erforderlich wäre. (Bild: © Zamrznuti tonovi - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/be/a9/bea9813088d28bae7b19799a194fe99c/0131951229v1.jpeg "Ewe hat seine Java-Umgebung über mehr als 100 Anwendungen und Zehntausende Desktop-Arbeitsplätze standardisiert. Nach Angaben des Unternehmens sanken dadurch die Java-Lizenzkosten um 60 Prozent. (Bild: © RomanR - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/1c/2e/1c2e0effc700eddefcf2264786aef800/0131879187v1.jpeg "Siemens erweitert sein Portfolio für industrielle KI bei der Verarbeitung von Produktionsdaten und bei der Automatisierung von Engineering-Prozessen. (Bild: Midjourney / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/95/a7/95a74d5f20e7e05ab33efde3fdfb1008/0132474712v3.jpeg "Auf der \"ISC High Performance 2026\" präsentierten zahlreiche Hersteller neue Quantencomputer sowie Software und Integrationslösungen für hybride HPC-Umgebungen. (Bild: Alice&Bob)")
:quality(80)/p7i.vogel.de/wcms/63/38/63389b116419fdfba92da2a91ad4c4d2/0132481063v1.jpeg "Fehlende Rechenkapazitäten, geringe Investitionen und internationale Abhängigkeiten bremsen den Aufbau einer europäischen Quantenindustrie. (Bild: Midjourney / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/99/2b/992bf8039e0c0a2818d7c01508cc2fd5/0132147095v1.jpeg "Stephan Reitzenstein vor der Probenkammer der Elektronenstrahl-Lithographie-Anlage: Diese Anlage stellt die hochpräzise Nanostrukturen für skalierbare Quantenlichtquellen her. (Bild: Felix Noak)")
:quality(80)/p7i.vogel.de/wcms/d0/75/d075ceeb4de4543fd6446dd4b26825d2/0131796600v2.jpeg "Am 21. Mai 2026 hat Globa lFoundries den Geschäftszweig „Quantum Technology Solutions“ ins Leben gerufen, der zur Skalierung der Fertigungskapazitäten gedacht ist. Der Geschäftsbereich startet mit Kundenverträgen und einer Pipeline von Quanteninnovatoren, die darauf ausgerichtet sind, auf seiner Plattform zu skalieren, so Silicon Saxony. (Bild: frei lizenziert: Gerhard Altmann)")
:quality(80)/p7i.vogel.de/wcms/a9/a3/a9a38515d76d5d2bdbf552020689dd4c/0132133445v1.jpeg "Veraltete IT-Strukturen, steigende Sicherheitsanforderungen und moderne Workloads: Alles Gründe dafür, die Infrastruktur schrittweise zu modernisieren. Aber wie soll das gelingen, ohne den laufenden Betrieb zu gefährden? (Bild: © Chainarong - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/01/1e/011eecedd1890f96971d8c6334e59403/0131873319v2.jpeg "Das Bild visualisiert einen Zufallszahlengenerator, der auf Quantenfluktuationen beruht (Bild: Fraunhofer IPMS/KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/29/33/2933cd5e834f8070b6c6777334e0aa0e/0131690146v1.jpeg "Wie Unternehmen mit ausgealterten Daten und IT-Hardware ümgehen, ist auch und nicht zuletzt eine Frage der Sicherheit. (Bild: © VladaToday - stock.adobe.com / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/ab/65/ab65db7e99df89b1b486f75c13496180/0132419758v1.jpeg "Rechenzentrum ist nicht gleich Cloud. Über die Unterschiede zwischen Colocation und Cloud-Diensten und weshalb der Zugriff auf Daten wichtiger ist als der Standort der Infrastruktur. (Bild: Midjourney / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/de/01/de011e022cf7a4457aa686dfe2f20755/0132592633v1.jpeg "Blick auf's Kraftwerk Staudinger 2019: Hier plant Uniper die Entwicklung eines Rechenzentrumscampus mit Energieinfrastruktur. (Bild: Kraftwerk Staudinger - power plant Staudinger / Alban.py / CC BY-SA 2.0 / flickr.com)")
:quality(80)/p7i.vogel.de/wcms/47/67/47674acc2bfaf7b633e6a27e5796a056/0132591049v1.jpeg "Das Rechenzentrum in Ohio entsteht nicht im Eigentum von OpenAI. Der Konzern übernimmt vor allem die Rolle des langfristigen Mieters und Koordinators. (Bild: Midjourney / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/dd/3e/dd3e2627864aea6931a85a604ecb9048/0132529570v1.jpeg "Gießen von oben: Im Industriegebiet „Katzenfeld“ soll ein Rechenzentrum entstehen. Was bislang bekannt ist. (Bild: THM Gießen / atxcowboy / CC BY-SA 2.0 / flickr.com)")
:quality(80)/p7i.vogel.de/wcms/48/fa/48fae955ace458bfeb45fb69c5f1cf83/0132525775v1.jpeg "Helmut Kohl spricht sich für einen stärker dezentralen Ausbau der Rechenzentrumslandschaft aus. (Bild: Midjourney / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/f3/da/f3dacd38e5834ae3f3c9d0a4bc9664d3/0113348475.jpeg "Das vom Umweltbundesamt beauftragte Projekt „Public Energy Efficiency Register of Data Centres “ (PeerDC), ist nach Einschätzung der Beteiligten Marina Köhn (UBA), Peter Radgen (IER Uni Stuttgart) und Felix Behrens (Öko-Institut e.V.) ein Erfolg auf ganzer Linie. Das sah DataCenter-Chefredakteurin Ulrike Ostler nach dem DataCenter-Diaries Podcast #16 nicht ganz so rosa. (Bild: sdecoret - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/90/f5/90f56ec6cb3ddbdabca2162fd5477836/0113078524.jpeg "(Bild: Vogel IT-Medien GmbH)")
:quality(80)/p7i.vogel.de/wcms/0f/09/0f097990002b7600075e43c92af4a3fd/0110524571.jpeg "(Bild: frei lizenziert/Krystsina Radzewich)")
:quality(80)/p7i.vogel.de/wcms/66/ae/66ae9e32738784b57e2ad8c1a4b0986f/0109756744.jpeg "Eines der in Deutschland befindlichen NTT-Datacenter - in Hattersheim - und das PeerDC-Logo. (Bild: NTT Global Data Centers )")
:quality(80)/p7i.vogel.de/wcms/b6/2f/b62f5450fa983d6fba21ec3b64a51be3/0132542976v1.jpeg "Wenn man neben dem täglichen Betrieb die Lieferketten von Komponenten und die Bauaktivitäten misst, erscheint der Emissionsbeitrag von Rechenzentren in einem ganz anderen Licht, so Alliance Research. (Bild: Daniel Schrader / GPT Image 2 / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/ee/3f/ee3f063b82737f0369c09ba7854587b5/0127234708v1.jpeg "Das sind die Gewinner der IT-Awards 2025! (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/f1/f0/f1f007a4518fa65d3cb0ea5ca465142a/0121300054v3.jpeg "Strahlende Gesichter bei allen, die die Preise des 10. DataCenter-Insider Award am gestrigen 17. Oktober abholen durften - in den Kategorien: Schnelles Interconnect, Infrastruktur der Resilienz, Coole Kühlung, HPC- und KI-Hardware, Grünes Co-Location und Cloud-native Plattformen. (Bild: Manuel Emme Fotografie)")
:quality(80)/p7i.vogel.de/wcms/a8/28/a828f76369267628d833a12c26dd6579/0121131534v3.jpeg "DataCenter-Insider verleiht heute die IT-Awards 2024 in sechs Kategorien. (Bild: Vogel IT-Medien)")
Eine andere Art APIs zu implementieren GraphQL als Alternative zu REST
„Facebook GraphQL“ wirft wesentliche Prinzipien klassischer REST-Architekturen über Bord. Angesichts der zunehmenden Popularität von GraphQL lohnt es sich aber, einen genaueren Blick darauf zu werfen und es gegebenenfalls für eigene Projekte in Betracht zu ziehen.
Anbieter zum Thema
:fill(fff,0)/p7i.vogel.de/companies/64/e4/64e4be0db6ddc/rittal-4c-w.png "rittal-4c-w (Rittal GmbH & Co. KG)")
Roy Fielding veröffentlichte seine Dissertation über RESTful Applications im Jahre 2000. Heute ist sein Architektur-Stil einer der wichtigsten und am weitesten verbreiteten bei Diensten im Internet. Leider sind REST-basierte Schnittstellen nicht immer optimal auf den jeweiligen Anwendungsfall zugeschnitten.
So kann es zu dem Problem kommen, dass der Client beim Aufruf einer Schnittstelle entweder zu viele oder zu wenige Daten als Response erhält. Bei zu vielen Daten spricht man von Over-Fetching. Bei zu wenigen Daten spricht man dagegen von Under-Fetching, wobei dann mindestens ein weiterer Request notwendig wird, um wirklich alle notwendigen Daten zu bekommen.
Beide Fälle sind schlecht für die Performance der Anwendung, da unnötig große oder unnötig viele Anfragen und Antworten verschickt werden. Je nach Anwendungsfall ist dieser Performance-Verlust mehr oder weniger relevant. Beispielsweise kann es bei mobilen Anwendungen aus diesem Grund zu Verzögerungen kommen.
Die Waage zwischen Requests und Responses
Eine mögliche Maßnahme gegen dieses Problem ist es, pro Anwendungsfall eine individuelle Schnittstelle zu implementieren, so dass die Größe und Menge der Requests und Responses immer optimal ist. Dies führt allerdings fast immer zu einer unüberschaubar großen Menge an Schnittstellen für die API.
Die Schnittstellen müssen daher zwangsläufig mehr oder wenig generisch entwickelt werden, um eine gesunde Balance zwischen Abstraktion und Menge der Schnittstellen zu erhalten. Under- und Over-Fetching müssen bei diesen generischen Schnittstellen teilweise billigend in Kauf genommen werden.
Query Strings für mehr Flexibilität
Ein weiterer Lösungsansatz für die Minimierung von Under- und Over-Fetching ist die Nutzung von Query Strings. Letztere werden pro REST-Schnittstelle verwendet, um diese flexibler zu machen. So wird beispielsweise in der Abfrage …
/users?select=name,email… mit dem Query String select die Response einer Benutzerschnittstelle /users auf den Namen und die E-Mail der Benutzer reduziert, um den Payload der Response zu verkleinern. Häufig wird mithilfe dieses Ansatzes gleichzeitig auch das Sortieren, Filtern und Paginieren implementiert. Alle eben genannten Mechanismen wirken dem Over-Fetching entgegen.
Um auch das Under-Fetching mithilfe von Query Strings zu minimieren, kann ein so genannter include- oder expand-Parameter verwendet werden. So würde beispielsweise …
/user/2?include=friends… bewirken, dass die Response der Benutzerschnittstelle für den Benutzer mit der ID 2 nicht nur eine Liste mit Links zu den Ressourcen der Freunde des Benutzers enthält, sondern dessen bereits aufgeschlüsselte Entitäten. Somit werden weitere Anfragen eingespart, falls die Ressourcen der Freunde direkt benötigt werden.
In der Regel steigt mit der Anzahl der Query Strings auch die Komplexität bei der Implementierung. Nicht selten wird an dieser Stelle mühsam eine eigene Abfragesprache entwickelt. Dass hierbei keine Standards existieren (abgesehen von Microsofts Open Data Protocol), macht diese Aufgabe häufig schwierig und fehleranfällig.
GraphQL als Alternative
GraphQL funktioniert prinzipiell ähnlich wie der zuvor beschriebene Lösungsansatz mit den Query Strings. Der Client kann mithilfe einer standardisierten GraphQL-Abfragesprache genau spezifizieren, welche Daten er abfragen beziehungsweise manipulieren möchte.
In GraphQL werden die Daten dabei nicht wie in REST als Ressourcen gesehen, sondern als Knoten, die über verschiedene Relationen (Kanten) miteinander verbunden sind und insgesamt einen Graphen ergeben. Daher auch der Name GraphQL, wobei QL für Query Language (Abfragesprache) steht.
Technisch betrachtet wird bei GraphQL die gesamte API auf eine einzige Schnittstelle reduziert, die alle Anfragen des Clients entgegennimmt. Diese Requests beinhalten jeweils zwei unterschiedliche Arten von GraphQL-Abfragen:
- Lesende Abfragen
- Manipulierende Abfragen

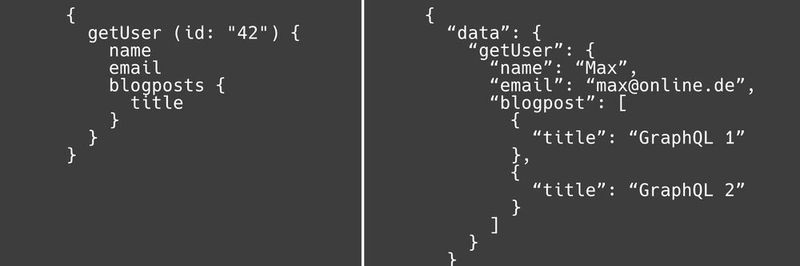
Das vorangestellte Beispiel zeigt links eine lesende Abfrage, die den Benutzer mit der ID 42 abfragt und rechts die Antwort des Servers auf diese Abfrage. Es werden der Name, die E-Mail und die Titel seiner Blog-Beiträge abgefragt.
Dadurch, dass benötigte Felder explizit angegeben werden können, wird das Over-Fetching verhindert. Ebenso wird das Under-Fetching umgangen, da die Titel der Blogbeiträge nicht in einem weiteren Request angefragt werden müssen, sondern direkt in der ersten Abfrage angeben werden können.
Wie ist ein GraphQL-Server zu implementieren?

Eine GraphQL-Schnittstelle Server-seitig zur Verfügung zu stellen, ist ähnlich einfach und intuitiv wie das Erstellen von Abfragen. Im Wesentlichen müssen Schema und Resolve-Funktionen definiert werden. Das Schema definiert die Knoten und die Relationen des Graphen, der die eigentlichen Daten darstellt.
Bezogen auf das vorherige Beispiel mit dem Benutzer würde der Graph mit zugehörigen Typ-Definitionen wie folgt aussehen:
Der Query-Datentyp bildet den Einstieg des Schemas und ist somit der Startknoten im Graphen. Das bedeutet, dass jede Abfrage des Clients mit einem der Felder des Query-Datentyps beginnen muss, da die Felder die Kanten im Graphen darstellen. Vom Startknoten ausgehend können alle anderen Knoten des Graphen erreicht werden.
Während innerhalb des Schemas die Datentypen und die Relationen zueinander definiert werden, beschreiben die Resolve-Funktionen, wie beziehungsweise woher die eigentlichen Daten geladen werden. Sie legen fest, wie die Felder oder Typen des Schemas mit einem oder mehreren Backends verbunden sind. Woher genau die Daten kommen, ist nicht festgelegt. So ist es möglich, in einer Resolve-Funktion beispielsweise eine REST-Schnittstelle aufzurufen oder direkt eine Datenbank anzufragen.
Nachdem Schema und Resolver implementiert worden sind, kann die Abfrage des Clients ausgewertet werden. Dies erfolgt in drei Schritten:
- 1. Parsen: Hier findet eine rein syntaktische Prüfung der Abfrage statt.
- 2. Validieren: Hier wird die Abfrage mithilfe des Schemas validiert. Es wird geprüft, ob die Felder der Abfrage mit denen des Schemas übereinstimmen.
- 3. Ausführen: Ausgehend vom Startknoten (Query-Datentyp) werden die Resolve-Funktionen der Felder ausgeführt, um das in der Abfrage angeforderte Datenobjekt nacheinander zusammen zu bauen.
Vor- und Nachteile von GraphQL
GraphQL löst unter anderem das Problem mit Over- und Under-Fetching in einer intuitiven und einfachen Art und Weise. Anders als in REST-basierten APIs muss der Entwickler keine eigene Abfragesprache entwickeln, um die API beziehungsweise Schnittstellen flexibler zu machen, sondern kann dafür auf GraphQL als Standard mit entsprechenden Referenzimplementierungen zurückgreifen.
Darüber hinaus wird gegenüber REST-basierter APIs die Kopplung zwischen Client und Server verringert, da der Client nicht mehr auf vorgefertigte und spezialisierte Schnittstellen angewiesen ist. Stattdessen können die im Kontext des Clients benötigten Daten individuell angefragt beziehungsweise manipuliert werden.
Der Client wird vom reinen Konsumenten zum Ersteller seiner eigenen Schnittstellen. Dies ist unter anderem dann hilfreich, wenn dieselbe API für unterschiedliche Plattformen – wie iOS, Android oder Web – verwendet werden soll.
Alle diese Vorteile kommen auch mit einer Reihe von Nachteilen. Themen wie beispielsweise Fehlerbehandlung, Caching oder Autorisation sind in GraphQL teilweise schwieriger umzusetzen, als in REST. Außerdem werden einige Themen in der Spezifikation nicht erwähnt, wie beispielsweise das Hochladen von Dateien. An diesen Stellen kann jedoch meistens auf Best Practices zurückgegriffen werden.

Insgesamt kann GraphQL je nach Anwendungsfall eine gute Alternative zu REST-basierten APIs sein. Besonders wenn die Schnittstellen sehr flexibel sein müssen, kann GraphQL den Aufwand der Implementierung reduzieren. In jedem Fall ist es nötig, REST und GraphQL zunächst nach Anwendungsfall beziehungsweise Anforderungen gegeneinander abzuwägen und erst dann eine Entscheidung zu treffen.
*David Klassen hat Informatik an der TU Dortmund studiert und ist aktuell Software Engineer bei der Adesso AG. Dort beschäftigt er sich neben Kundenprojekten mit der Nutzung und Weiterentwicklung von Open-Source-Software. In diesem Zusammenhang hat er bereits erfolgreich selber an einigen Open-Source-Projekten mitgewirkt.
(ID:45498642)
:quality(80)/p7i.vogel.de/wcms/c5/62/c562d5635700b17bca787b9735677868/0128496593v2.jpeg "Datenbankverwaltung über PHP mit direktem Zugriff auf Strukturen, Benutzer und SQL (Bild: Thomas Joos)")
:quality(80)/p7i.vogel.de/wcms/58/82/5882febb849543c966f51830c3375b25/0127692320v1.jpeg "Die „Sphere“, die in der Nähe des Veranstaltungsorts der „Oracle AI World“ liegt, erstrahlt zu diesem Anlass mit dem Oracle-Logo. (Bild: Oracle)")