
:quality(80)/p7i.vogel.de/wcms/8b/ae/8baee103debba73f2362593fc17d79fc/0132543354v1.jpeg "PUE zeigt Effizienz. Intelligente Laststeuerung entscheidet darüber, wie viel Rechenleistung ein Standort aus seiner verfügbaren Energie- und Netzkapazität herausholt, so Torge Lahrsen. (Bild: Daniel Schrader / GPT Image 2 / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/44/3a/443a4cb166a005757c21dd48a5ae8a26/0132505426v1.jpeg "CPU, GPU, Netzwerk und Software stammen aus dem AMD-Portfolio. Gemeinsam mit Supermicro entsteht eine durchgängige Infrastruktur für KI-Training und Inferenz. (Bild: Gemini / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/b6/2f/b62f5450fa983d6fba21ec3b64a51be3/0132542976v1.jpeg "Wenn man neben dem täglichen Betrieb die Lieferketten von Komponenten und die Bauaktivitäten misst, erscheint der Emissionsbeitrag von Rechenzentren in einem ganz anderen Licht, so Alliance Research. (Bild: Daniel Schrader / GPT Image 2 / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/4d/10/4d10f7835ecfc83e760fd96d3b7f1336/0132481780v1.jpeg "KI-Rechenzentren erreichen neue Größenordnungen. Mit steigender Rechenleistung wachsen auch die Anforderungen an Energieversorgung, Kühlung und Infrastruktur. (Bild: Midjourney / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/e8/d4/e8d462ed9972be2b8464c790cce263c0/0132429621v1.jpeg "Die Integration der KI-gestützten Designexploration von Precision Innovations soll die Silizium-Chip-Entwicklung beschleunigen, so Siemens. (Bild: Siemens)")
:quality(80)/p7i.vogel.de/wcms/37/0a/370aa88021e97f80526e1d07f8a64ca9/0132435873v1.jpeg "Die „ND MI455X v7“-Serie basiert auf AMDs Rackscale-Design und soll Reasoning- und Suchanwendungen sowie KI-Agenten in Azure beschleunigen. (Bild: Midjourney / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/0b/0e/0b0ef1fc1c379ab914c58f63a1ea58be/0132441193v1.jpeg "Storage-Schichten, geo-verteilte Datenhaltung und offene Standards sind die Grundlage für resiliente und souveräne Infrastrukturen. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/67/c3/67c399c0d42006c206b19ca13a408732/0132302716v1.jpeg "AI Restacking integriert Künstliche Intelligenz in alle Ebenen der Unternehmensarchitektur. Geschäftsprozesse, Daten, Anwendungen und Technologien bilden dabei ein vernetztes System, das kontinuierlich aus Daten und Feedback lernt. (Bild: © BalanceFormCreative - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/73/8d/738d892859c9bf552bffeaee476c1bc3/0132416407v1.jpeg "Die Architektur soll KI-Inferenz, Container und virtuelle Maschinen an dezentralen Standorten sichern. (Bild: © Starmarpro - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/bb/84/bb848b79900a103b8aaed3207f1f1055/0132159005v1.jpeg "KI verändert die Wirtschaftlichkeit von Cloud-Infrastrukturen grundlegend. Wer Ressourcen weiterhin statisch bereitstellt, zahlt oft deutlich mehr als technisch erforderlich wäre. (Bild: © Zamrznuti tonovi - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/be/a9/bea9813088d28bae7b19799a194fe99c/0131951229v1.jpeg "Ewe hat seine Java-Umgebung über mehr als 100 Anwendungen und Zehntausende Desktop-Arbeitsplätze standardisiert. Nach Angaben des Unternehmens sanken dadurch die Java-Lizenzkosten um 60 Prozent. (Bild: © RomanR - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/1c/2e/1c2e0effc700eddefcf2264786aef800/0131879187v1.jpeg "Siemens erweitert sein Portfolio für industrielle KI bei der Verarbeitung von Produktionsdaten und bei der Automatisierung von Engineering-Prozessen. (Bild: Midjourney / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/74/74/7474bd5b4077a876d07eedacc3829cf1/0131673379v1.jpeg "Datacenter sind nicht nur eine Immobilie; sie sind heute Teil der Wärme- und Strom-Infrastruktur, sind als Daten- und Kommunikationsschlüssel systemrelevant und unterliegen damit den KRITIS-DACH- und NIS-2-Gesetzen sowie Reporting-Pflichten. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/95/a7/95a74d5f20e7e05ab33efde3fdfb1008/0132474712v3.jpeg "Auf der \"ISC High Performance 2026\" präsentierten zahlreiche Hersteller neue Quantencomputer sowie Software und Integrationslösungen für hybride HPC-Umgebungen. (Bild: Alice&Bob)")
:quality(80)/p7i.vogel.de/wcms/63/38/63389b116419fdfba92da2a91ad4c4d2/0132481063v1.jpeg "Fehlende Rechenkapazitäten, geringe Investitionen und internationale Abhängigkeiten bremsen den Aufbau einer europäischen Quantenindustrie. (Bild: Midjourney / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/99/2b/992bf8039e0c0a2818d7c01508cc2fd5/0132147095v1.jpeg "Stephan Reitzenstein vor der Probenkammer der Elektronenstrahl-Lithographie-Anlage: Diese Anlage stellt die hochpräzise Nanostrukturen für skalierbare Quantenlichtquellen her. (Bild: Felix Noak)")
:quality(80)/p7i.vogel.de/wcms/d0/75/d075ceeb4de4543fd6446dd4b26825d2/0131796600v2.jpeg "Am 21. Mai 2026 hat Globa lFoundries den Geschäftszweig „Quantum Technology Solutions“ ins Leben gerufen, der zur Skalierung der Fertigungskapazitäten gedacht ist. Der Geschäftsbereich startet mit Kundenverträgen und einer Pipeline von Quanteninnovatoren, die darauf ausgerichtet sind, auf seiner Plattform zu skalieren, so Silicon Saxony. (Bild: frei lizenziert: Gerhard Altmann)")
:quality(80)/p7i.vogel.de/wcms/a9/a3/a9a38515d76d5d2bdbf552020689dd4c/0132133445v1.jpeg "Veraltete IT-Strukturen, steigende Sicherheitsanforderungen und moderne Workloads: Alles Gründe dafür, die Infrastruktur schrittweise zu modernisieren. Aber wie soll das gelingen, ohne den laufenden Betrieb zu gefährden? (Bild: © Chainarong - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/01/1e/011eecedd1890f96971d8c6334e59403/0131873319v2.jpeg "Das Bild visualisiert einen Zufallszahlengenerator, der auf Quantenfluktuationen beruht (Bild: Fraunhofer IPMS/KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/29/33/2933cd5e834f8070b6c6777334e0aa0e/0131690146v1.jpeg "Wie Unternehmen mit ausgealterten Daten und IT-Hardware ümgehen, ist auch und nicht zuletzt eine Frage der Sicherheit. (Bild: © VladaToday - stock.adobe.com / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/16/3c/163ca34e83af8b229e3babcdfbdfeeaf/0131682376v1.jpeg "Zu sehen ist das Äußere des Halbleiter-Leistungsschalters „Sentron 3QD2“. (Bild: Siemens)")
:quality(80)/p7i.vogel.de/wcms/ab/65/ab65db7e99df89b1b486f75c13496180/0132419758v1.jpeg "Rechenzentrum ist nicht gleich Cloud. Über die Unterschiede zwischen Colocation und Cloud-Diensten und weshalb der Zugriff auf Daten wichtiger ist als der Standort der Infrastruktur. (Bild: Midjourney / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/dd/3e/dd3e2627864aea6931a85a604ecb9048/0132529570v1.jpeg "Gießen von oben: Im Industriegebiet „Katzenfeld“ soll ein Rechenzentrum entstehen. Was bislang bekannt ist. (Bild: THM Gießen / atxcowboy / CC BY-SA 2.0 / flickr.com)")
:quality(80)/p7i.vogel.de/wcms/48/fa/48fae955ace458bfeb45fb69c5f1cf83/0132525775v1.jpeg "Helmut Kohl spricht sich für einen stärker dezentralen Ausbau der Rechenzentrumslandschaft aus. (Bild: Midjourney / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/86/09/8609f09c002a7a70aaf3bc21e36e02ca/0132458169v1.jpeg "Nach geplatzem Oracle-Deal aufgrund von US-Sicherheitsauflagen kauft sich Microsoft bei Mistral in Europa ein. (Bild: Gemini / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/c5/53/c5536e8ca2739f5d84243953e9116e47/0132446644v1.jpeg "Der Campus von Green Mountain und KMW entsteht auf der Ingelheimer Aue in Mainz, direkt am Rhein. (Bild: Green Mountain)")
:quality(80)/p7i.vogel.de/wcms/f3/da/f3dacd38e5834ae3f3c9d0a4bc9664d3/0113348475.jpeg "Das vom Umweltbundesamt beauftragte Projekt „Public Energy Efficiency Register of Data Centres “ (PeerDC), ist nach Einschätzung der Beteiligten Marina Köhn (UBA), Peter Radgen (IER Uni Stuttgart) und Felix Behrens (Öko-Institut e.V.) ein Erfolg auf ganzer Linie. Das sah DataCenter-Chefredakteurin Ulrike Ostler nach dem DataCenter-Diaries Podcast #16 nicht ganz so rosa. (Bild: sdecoret - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/90/f5/90f56ec6cb3ddbdabca2162fd5477836/0113078524.jpeg "(Bild: Vogel IT-Medien GmbH)")
:quality(80)/p7i.vogel.de/wcms/0f/09/0f097990002b7600075e43c92af4a3fd/0110524571.jpeg "(Bild: frei lizenziert/Krystsina Radzewich)")
:quality(80)/p7i.vogel.de/wcms/66/ae/66ae9e32738784b57e2ad8c1a4b0986f/0109756744.jpeg "Eines der in Deutschland befindlichen NTT-Datacenter - in Hattersheim - und das PeerDC-Logo. (Bild: NTT Global Data Centers )")
:quality(80)/p7i.vogel.de/wcms/ee/3f/ee3f063b82737f0369c09ba7854587b5/0127234708v1.jpeg "Das sind die Gewinner der IT-Awards 2025! (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/f1/f0/f1f007a4518fa65d3cb0ea5ca465142a/0121300054v3.jpeg "Strahlende Gesichter bei allen, die die Preise des 10. DataCenter-Insider Award am gestrigen 17. Oktober abholen durften - in den Kategorien: Schnelles Interconnect, Infrastruktur der Resilienz, Coole Kühlung, HPC- und KI-Hardware, Grünes Co-Location und Cloud-native Plattformen. (Bild: Manuel Emme Fotografie)")
:quality(80)/p7i.vogel.de/wcms/a8/28/a828f76369267628d833a12c26dd6579/0121131534v3.jpeg "DataCenter-Insider verleiht heute die IT-Awards 2024 in sechs Kategorien. (Bild: Vogel IT-Medien)")
Maxine, Augen geradeaus! Nvidia liefert mit Jarvis vortrainierte Modelle für die Interpretation natürlicher Sprache
Wer das nicht toll, wenn alle, die in einem virtuellen Meeting oder einer virtuellen Konferenz sind, sich auch in die Augen schauten? Doch nur selten gucken alle geradeaus in die Kamera. Doch „Maxine“ kann das arrangieren. Mit dem Nvidia-Framework „Jarvis“ bietet der Hersteller vorgefertigte Deep-Learning-Modelle und Tools, mit denen sich (passende) KI-basierte Anwendungen zur Sprachkommunikation erstellen lassen.
Anbieter zum Thema
:fill(fff,0)/images.vogel.de/vogelonline/companyimg/107300/107370/65.png "pressebox_600x600_v2.png ()")
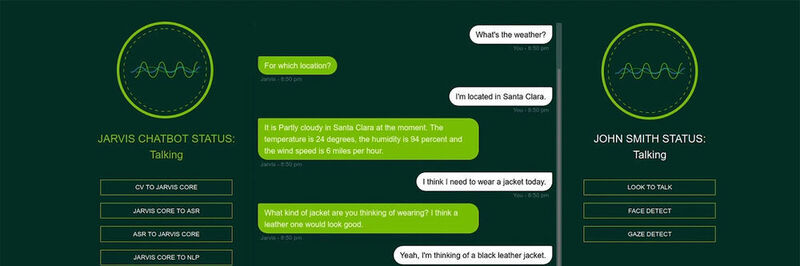
Das Framework erlaubt Anwendungen, in denen natürliche Sprache erkannt, übersetzt und in Text umgewandelt wird, und zwar quasi on the fly. Dank GPU-Beschleunigung kanneine End-to-End-Sprachpipeline in weniger als 100 Millisekunden ausgeführt werden. Die Software hört zu, versteht und generiert eine Antwort schneller als ein menschlicher Wimpernschlag.
Das kann in der Cloud, im Rechenzentrum oder der Edge eingesetzt werden und das bedeutet die Möglichkeit einer sofortigen Skalierung auf Millionen von Benutzern. Unterstützt wird etwa Englisch, Koreanisch und Deutsch. Einer der ersten Anwender ist T-Mobile in den USA.
In seiner Keynote zur Konferenz GTC21, die in der vergangenen Woche stattgefunden hat, hat Nvidia-Chef Jensen Huang eine neue Welle von sprachbasierten Anwendungen in Aussicht gestellt, die bisher unmöglich zu realisieren waren oder nur von den ganz großen Konzernen und die die Interaktion zwischen Mensch und Maschine verbessern können:
- digitale Krankenschwestern, die helfen, Patienten rund um die Uhr zu überwachen und überlastetes medizinisches Personal zu entlasten;
- Online-Assistenten, die verstehen, wonach Verbraucher suchen und die besten Produkte empfehlen;
- Echtzeitübersetzungen, um die grenzüberschreitende Zusammenarbeit am Arbeitsplatz zu verbessern und Zuschauern zu ermöglichen, Live-Inhalte in ihrer eigenen Sprache zu verfolgen.
Jarvis wurde mit Hilfe von Modellen entwickelt, die mehrere Millionen GPU-Stunden lang auf über 1 Milliarde Textseiten und 60.000 Stunden Sprachdaten trainiert wurden, und zwar in verschiedenen Sprachen, Akzenten, Umgebungen und Jargons.
Entwickler, die Jarvis benutzen wollen, können das Framework „TAO“ nutzen. Damit lassen sich die vorhandenen Modelle für spezifische Aufgaben, Branchen und Systeme trainieren, anpassen und optimieren. Sie wählen dazu aus dem „NGC“-Katalog von Nvidia ein mit Jarvis trainiertes Modell aus. Das Transfer Learning Toolkit hilft dabei diese auf die eigenen Daten abzustimmen, es für Durchsatz und Latenz in Echtzeit-Sprachdiensten zu optimieren. Das Modell lässt sich dann laut Nividia mit nur wenigen Zeilen Code einsetzen, so dass kein tiefes KI-Fachwissen erforderlich sei.
Das berichten die Anwender
Matthew Davis, Vice President of Product and Technology bei T-Mobile USA, sagt: „Nach der Evaluierung mehrerer automatischer Spracherkennungstechniken hat T-Mobile festgestellt, dass Jarvis ein Qualitätsmodell mit extrem niedriger Latenz liefert, das Erfahrungen ermöglicht, die unsere Kunden lieben.“
Nvidia arbeitet auch mit Mozilla Common Voice zusammen, einer Open-Source-Sammlung von Sprachdaten für Startups, Forscher und Entwickler, um sprachgesteuerte Apps, Dienste und Geräte zu trainieren. Common Voice ist der weltweit größte mehrsprachige, öffentlich zugängliche Sprachdatensatz und enthält insgesamt über 9.000 Stunden an Sprachdaten in 60 verschiedenen Sprachen. Nvidia nutzt Jarvis, um mit dem Datensatz vortrainierte Modelle zu entwickeln und diese dann der Community kostenlos zur Verfügung zu stellen.
„Wir haben Common Voice ins Leben gerufen, um Maschinen beizubringen, wie echte Menschen in ihren einzigartigen Sprachen, Akzenten und Sprachmustern sprechen“, führt Mark Surman aus, Executive Director bei Mozilla. „Nvidia und Mozilla haben die gemeinsame Vision, die Sprachtechnologie zu demokratisieren - und sicherzustellen, dass sie die reiche Vielfalt an Menschen und Stimmen widerspiegelt, die das Internet ausmachen.“
Die zur GTC21 angekündigte Jarvis Funktionen werden im zweiten Quartal des Jahres im Rahmen des laufenden offenen Beta-Programms veröffentlicht. Entwickler können es bereits vom herunterladen.
Treffen mit Maxine
Maxine ist ein GPU-beschleunigtes SDK von Nvidia mit KI-Funktionen für Entwickler. Entwickler können das Toolkit nutzen, um Anwendungen für virtuelle Zusammenarbeit und für die Content-Erstellung, etwa Video-Konferenzen und Live-Streaming, zu erstellen. Sie finden bereits optimierte Video- und Audio-Effekte sowie Augmented Reality (AR) vor, die sie zu einer End-to-End-Pipelines verketten können, Das gilt sowohl für GPU-Anwendungen in Rechenzentren als auch auf PCs. Außerdem lässt sich Maxine mit Jarvis verwenden.
(ID:47355004)
:quality(80)/p7i.vogel.de/wcms/d7/34/d734d039862517977b8c5ff09e41cb4e/0129989320v1.jpeg "Die neue AI-native Cloud verschiebt das Grundprinzip der Cloud von einer Ressourcen-orientierten Architektur mit virtuellen Maschinen hin zu einer Funktionalitäts-orientierten Welt mit KI-Modell-APIs. (Bild: © fotomek - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/7f/39/7f3904c8e34848303d65dcb8fa84bef0/0126326548v1.jpeg "Im Bild: Die Kühlanlagen auf dem Dach des „Modular Data Centre“, in dem „Jupiter“untergebracht ist. Mit mehr als 60 Milliarden Rechenoperationen pro Watt ist Jupiter der effizienteste unter den fünf leistungsfähigsten Superrechnern der Welt. (Bild: Forschungszentrum Jülich/Sascha Kreklau)")