
:quality(80)/p7i.vogel.de/wcms/d4/3b/d43b7836de769e65b766932925d2ef40/0132242200v1.jpeg "KI-Cluster benötigen leistungsfähige Interconnects, damit tausende GPUs mit geringer Latenz und hoher Bandbreite zusammenarbeiten können. (Bild: Midjourney / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/ad/1c/ad1ca8d7eab7d0c398db520687586a57/0132253970v1.jpeg "SNP, die schottische Regierungspartei, hatte sich noch Anfang 2026 gegen ein Datacenter-Moratorium ausgesprochen. Jetzt vollzieht sie eine Kehrtwende, sodass in Holyrood eine Mehrheit für ein temporäres Bauverbot möglich wird. (Bild: Yves Grandmontagne /DCmag)")
:quality(80)/p7i.vogel.de/wcms/1f/a8/1fa8fd131fcfb660575dc576e9452be6/0132195461v1.jpeg "Laut Schneider Electrics ist die Chiller-Baureihe für Rechenzentrumsbetreiber, die auf Liquid Cooling für KI- und Hochleistungsrechnen (HPC) umstellen oder bereits umgestellt haben, gedacht. (Bild: Midjourney / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/25/ba/25ba46cb0d57f75776466da277dac3ff/0132182757v1.jpeg "Mit steigender GPU-Dichte wachsen auch die Anforderungen an die Leistungsfähigkeit und Skalierbarkeit der Storage-Infrastruktur. (Bild: © Gorodenkoff - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/15/ea/15ea1df84828bc547f77a6365d34714d/0132117598v1.jpeg "Nvidia bietet kapitalschwächeren Cloud-Anbietern KI-Beschleuniger gegen Nutzungsgebühren und Gewinnbeteiligung an. (Bild: Nvidia)")
:quality(80)/p7i.vogel.de/wcms/bb/84/bb848b79900a103b8aaed3207f1f1055/0132159005v1.jpeg "KI verändert die Wirtschaftlichkeit von Cloud-Infrastrukturen grundlegend. Wer Ressourcen weiterhin statisch bereitstellt, zahlt oft deutlich mehr als technisch erforderlich wäre. (Bild: © Zamrznuti tonovi - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/4d/ef/4def98d350a28359460e482100e1d3d8/0132138749v1.jpeg "V.l..: Georg Schmidt-Reindahl (Eplan), Marc Walter (Rittal), Uwe Scharf (Rittal), Tobias Funke (TOBOL), Cornelia Müller (Rittal) Steffen Schmidt (Rittal) und Philipp Müller (Rittal) (Bild: Rittal)")
:quality(80)/p7i.vogel.de/wcms/a9/a3/a9a38515d76d5d2bdbf552020689dd4c/0132133445v1.jpeg "Veraltete IT-Strukturen, steigende Sicherheitsanforderungen und moderne Workloads: Alles Gründe dafür, die Infrastruktur schrittweise zu modernisieren. Aber wie soll das gelingen, ohne den laufenden Betrieb zu gefährden? (Bild: © Chainarong - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/b5/d4/b5d418de82fbb8e8f06b04d5eced180a/0132015300v1.jpeg "Die KI soll in etwa fünf Jahren Energie-Optimierung, Predictive Maintenance, Ressourcenzuordnung , zum Beispiel von CPU, GPU und Bandbreite, orchestrieren können. Doch diese agentische Steuerungsebene wird nicht nur zum Produktivitätshebel, sondern auch zu einer hochprivilegierten Angriffsfläche. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/be/a9/bea9813088d28bae7b19799a194fe99c/0131951229v1.jpeg "Ewe hat seine Java-Umgebung über mehr als 100 Anwendungen und Zehntausende Desktop-Arbeitsplätze standardisiert. Nach Angaben des Unternehmens sanken dadurch die Java-Lizenzkosten um 60 Prozent. (Bild: © RomanR - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/1c/2e/1c2e0effc700eddefcf2264786aef800/0131879187v1.jpeg "Siemens erweitert sein Portfolio für industrielle KI bei der Verarbeitung von Produktionsdaten und bei der Automatisierung von Engineering-Prozessen. (Bild: Midjourney / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/74/74/7474bd5b4077a876d07eedacc3829cf1/0131673379v1.jpeg "Datacenter sind nicht nur eine Immobilie; sie sind heute Teil der Wärme- und Strom-Infrastruktur, sind als Daten- und Kommunikationsschlüssel systemrelevant und unterliegen damit den KRITIS-DACH- und NIS-2-Gesetzen sowie Reporting-Pflichten. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/99/2b/992bf8039e0c0a2818d7c01508cc2fd5/0132147095v1.jpeg "Stephan Reitzenstein vor der Probenkammer der Elektronenstrahl-Lithographie-Anlage: Diese Anlage stellt die hochpräzise Nanostrukturen für skalierbare Quantenlichtquellen her. (Bild: Felix Noak)")
:quality(80)/p7i.vogel.de/wcms/d0/75/d075ceeb4de4543fd6446dd4b26825d2/0131796600v2.jpeg "Am 21. Mai 2026 hat Globa lFoundries den Geschäftszweig „Quantum Technology Solutions“ ins Leben gerufen, der zur Skalierung der Fertigungskapazitäten gedacht ist. Der Geschäftsbereich startet mit Kundenverträgen und einer Pipeline von Quanteninnovatoren, die darauf ausgerichtet sind, auf seiner Plattform zu skalieren, so Silicon Saxony. (Bild: frei lizenziert: Gerhard Altmann)")
:quality(80)/p7i.vogel.de/wcms/01/1e/011eecedd1890f96971d8c6334e59403/0131873319v2.jpeg "Das Bild visualisiert einen Zufallszahlengenerator, der auf Quantenfluktuationen beruht (Bild: Fraunhofer IPMS/KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/6f/b7/6fb7ad8acdc584a2bfb3b9c28ae5cc29/0131860924v1.jpeg "Auf dem „Optica Quantum Summit 2.0“ stellt das Unternehmen in Glasgow vor, wie sie optische Übertragung in den Rechenprozess integrieren. (Bild: © Chanelle M/peopleimages.com - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/29/33/2933cd5e834f8070b6c6777334e0aa0e/0131690146v1.jpeg "Wie Unternehmen mit ausgealterten Daten und IT-Hardware ümgehen, ist auch und nicht zuletzt eine Frage der Sicherheit. (Bild: © VladaToday - stock.adobe.com / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/16/3c/163ca34e83af8b229e3babcdfbdfeeaf/0131682376v1.jpeg "Zu sehen ist das Äußere des Halbleiter-Leistungsschalters „Sentron 3QD2“. (Bild: Siemens)")
:quality(80)/p7i.vogel.de/wcms/b5/83/b5839e142c423a47b42433550f6ebbb5/0132253961v1.jpeg "Spezialisierte Neoclouds bieten einen scharfen KI-Fokus und suchen sich damit von dem breiten Portfolio der Hyperscaler abzusetzen. Ihr Marktanteil wächst beständig. (Bild: Daniel Schrader / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/dd/0a/dd0a2e101153798711f788fdf4fdd7e0/0131888564v1.jpeg "Die Partnerschaft soll dazu dienen, parallelen Hochleistungszugriff mit automatisiertem Datenmanagement und skalierbarer Langzeitarchivierung für KI-, HPC- und Big-Data-Umgebungen zu kombinieren. (Bild: © Rawpixel.com - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/01/25/01259ecb55d6f67a5bc2b2c00b1b383e/0131864837v3.jpeg "Der Supercomputer „Alps“ basiert auf dem System dem „Cray-EX“ von HPE. (Bild: CC BY-SA 3.0 / cscs.ch)")
:quality(80)/p7i.vogel.de/wcms/bf/a9/bfa9522af622dfe0fca8fcf1ae0f157b/0131569943v1.jpeg "Das Huang signierte Rack steht übrigens nicht zum Verkauf. Michael Dell hat das auf der Bühne klargestellt. Manche Symbole sind zu wertvoll für den freien Markt. Doch die Partnerschaft zwischen Dell und Nvidia länger hält als manche Dating-Beziehung, wird sich zeigen. (Bild: Paula Breukel)")
:quality(80)/p7i.vogel.de/wcms/02/75/02759dd74c0a3c0df4d22999cae350a1/0132208640v1.jpeg "Eisenach bekommt kein Rechenzentrum mit 300 MVA Anschlussleistung. Obwohl das Vorhaben weit fortgeschritten war, hat der Stadtrat das Projekt nun vorerst gestoppt. (Bild: Eisenach / Charlotta Wasteson/cwasteson / CC BY 2.0 / flickr.com)")
:quality(80)/p7i.vogel.de/wcms/3e/76/3e762ad103dac4a62d81cc05d0e8d8d5/0132205485v1.jpeg "Strom, Fläche, kaum Gewerbesteuer: Microsofts vierter NRW-Standort sorgt für Ärger, noch bevor der erste Spatenstich erfolgt ist. (Bild: Microsoft / Julien G. / CC BY 2.0 / flickr.com)")
:quality(80)/p7i.vogel.de/wcms/9b/74/9b7400774dbb0f4203d632733dd22aed/0132154902v1.jpeg "Wenn sich die Politik nicht schneller bewegt, bleibt Europas Vision eines verteilten Netzes leistungsfähiger KI-Gigafactories als Gegengewicht zu den US-Giganten ein bloßer Wunschtraum. (Bild: © NicoElNino - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/08/f2/08f20bf156b8751027de9aa84b25db10/0131012870v1.jpeg "Daten von OpenStreetMap - Veröffentlicht unter ODbL (Bild: OpenStreetMap)")
:quality(80)/p7i.vogel.de/wcms/f3/da/f3dacd38e5834ae3f3c9d0a4bc9664d3/0113348475.jpeg "Das vom Umweltbundesamt beauftragte Projekt „Public Energy Efficiency Register of Data Centres “ (PeerDC), ist nach Einschätzung der Beteiligten Marina Köhn (UBA), Peter Radgen (IER Uni Stuttgart) und Felix Behrens (Öko-Institut e.V.) ein Erfolg auf ganzer Linie. Das sah DataCenter-Chefredakteurin Ulrike Ostler nach dem DataCenter-Diaries Podcast #16 nicht ganz so rosa. (Bild: sdecoret - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/90/f5/90f56ec6cb3ddbdabca2162fd5477836/0113078524.jpeg "(Bild: Vogel IT-Medien GmbH)")
:quality(80)/p7i.vogel.de/wcms/0f/09/0f097990002b7600075e43c92af4a3fd/0110524571.jpeg "(Bild: frei lizenziert/Krystsina Radzewich)")
:quality(80)/p7i.vogel.de/wcms/66/ae/66ae9e32738784b57e2ad8c1a4b0986f/0109756744.jpeg "Eines der in Deutschland befindlichen NTT-Datacenter - in Hattersheim - und das PeerDC-Logo. (Bild: NTT Global Data Centers )")
:quality(80)/p7i.vogel.de/wcms/2a/90/2a906642044a7ddb2a3c49db6f2e1d26/0132054740v1.jpeg "Der experimentelle, im 0,7-Nanometer-Verfahren hergestellte Chip in den Fingerspitzen eines IBM-Forschers. (Bild: IBM)")
:quality(80)/p7i.vogel.de/wcms/e2/fc/e2fc5ae66726bf4e580099c75883d736/0132027377v2.jpeg "DIe Integration heterogener HPC-Umgebungen und digitale Souveränität waren wichtige Themen auf der Kongressmesse „ISC High Performance 2026“ in Hamburg. (Bild: Rüdiger)")
:quality(80)/p7i.vogel.de/wcms/ee/3f/ee3f063b82737f0369c09ba7854587b5/0127234708v1.jpeg "Das sind die Gewinner der IT-Awards 2025! (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/f1/f0/f1f007a4518fa65d3cb0ea5ca465142a/0121300054v3.jpeg "Strahlende Gesichter bei allen, die die Preise des 10. DataCenter-Insider Award am gestrigen 17. Oktober abholen durften - in den Kategorien: Schnelles Interconnect, Infrastruktur der Resilienz, Coole Kühlung, HPC- und KI-Hardware, Grünes Co-Location und Cloud-native Plattformen. (Bild: Manuel Emme Fotografie)")
:quality(80)/p7i.vogel.de/wcms/a8/28/a828f76369267628d833a12c26dd6579/0121131534v3.jpeg "DataCenter-Insider verleiht heute die IT-Awards 2024 in sechs Kategorien. (Bild: Vogel IT-Medien)")
Verteilte Daten, Datenbanken Datos IO mit Daten-Management für Backup und Recovery bei Multi-Cloud-Datenbanken
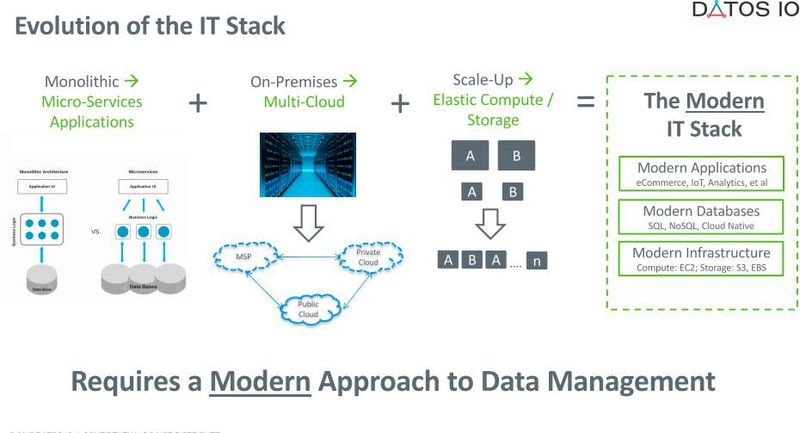
Moderne Applikationen werden heute meist verteilt in verschiedenen Umgebungen gelagert. Doch wer kümmert sich um die Datensicherung, wenn Applikation und Datenbank auf unterschiedlichen Cluster-Knoten vorrätig sind? Das Startup Datos IO hat dafür mit „Recover X“ ein umfassendes Daten-Management auf den Markt gebracht.
Anbieter zum Thema
Die Startup-Company aus San José im Silicon Valley wurde erst 2014 von Tarun Thakur und Prasentjit Sarkar gegründet, hat seither aber für Furore gesorgt. Während Thakur als CEO die Geschicke leitet, übernimmt Sarkar als CTO und Vordenker die technische Entwicklung. Er bezeichnet das Produkt Recover X als „Applikations-zentrierte Cloud-Management Software, die Backup und Recovery für moderne Anwendungen liefert“.
Heutige Applikationen sind praktisch „in der Cloud geboren“, das heißt: Sie sind für Cloud Computing entworfen worden. Sie nutzen nicht-relationale Datenbanken wie „MongoDB“, „Apache Cassandra“ oder andere. Der Vorteil nicht-relationaler Datenbanken besteht vor allem darin, dass sie hoch verfügbar sind; allerdings hapert es meist an der Datenkonsistenz.
Herkömmliche Anwendungen, die für das Rechenzentrum alter Prägung entworfen wurden und auf relationalen Datenbanken betrieben werden, wandern heute zunehmend ebenfalls in Cloud-Umgebungen. „Dafür reichen die klassischen Strategien für das Daten-Management aber nicht aus“, beschreibt Sarkar ein Problem, das Recover X lösen soll.

Das Verbindende ist der Content
Zeitgemäßes Daten-Management muss also die neuen Herausforderungen, die durch Multi-Cloud-Umgebungen entstanden sind, für neue und alte Applikationen erfüllen. Datos IO hat dazu folgende Überlegungen für ein neues Daten-Management angestellt:
- 1. Ein Bereitstellungsmodell, das nur auf Software basiert um mehr Flexibilität zu erhalten und dem Anwender die Wahl des gewünschten Speichers zu überlassen.
- 2. Da jede Cloud eine unterschiedliche Infrastruktur nutzt, sind der einzige gemeinsame Nenner die Daten selbst. „SCSI LUNs oder ESX virtuelle Maschinen existieren in der Public Cloud nicht. Das einzig Gemeinsame, das alle Clouds verbindet, sind die Daten selbst“, stellt der CTO fest.
- 3. Da Multi-Cloud-Datenbanken elastisch agieren, müssen die Datensicherheit und das Daten-Management hoch verfügbar, skalierbar und ausfallsicher sein.
- 4. Zudem werden neue Point-in-Time-Techniken für die Einhaltung der Datenkonsistenz innerhalb eines Clusters benötigt.
Den Verantwortlichen bei Datos IO war klar, dass sie mit den herkömmlichen Architekturen des Daten-Managements die Herausforderungen heutiger und zukünftiger IT-Strukturen nicht bewältigen können. Deshalb entwickelten sie ein vollkommen neues Design, das sie „Consistent Orchestrated Distributed Recovery“ (CODR) nannten.

RecoverX will auch zukünftige Scale-out-Datenbanken bändigen
„Der Vorteil unseres anwendungszentrierten Ansatzes ist eine feinkörnige und sehr platzsparende Lösung für Data Protection und Mobilität, die sich über Clouds auch jenseits von Netzverbindungen erstrecken kann“, beschreibt CTO Sarkar die Architektur. Ein zusätzlicher Vorteil der CODR-Engine bestehe darin, dass umfangreiche Daten-Management-Services wie Security, Data Governance und andere angeboten werden können. Damit unterscheide sich die Lösung von Datos IO fundamental von herkömmlichen Ansätzen, die auf virtuellen Maschinen oder LUN-basierenden beruhen und denen der Applikationsbezug fehle.
Eines der Elemente von CODR ist der Einsatz von Abstraktionen, die die Architektur von technischen Variationen der verschiedenen Datenquellen trennen. Als Beispiel nennt Datos IO die Verwendung des Open Database Connectivity (ODBC) API, um damit Datenbank-Management-Systeme (DBMS) zu erreichen. Eine Applikation, die ODBC verwendet, kann auf andere Plattformen – sowohl auf Client- als auch auf Server-Seite – portiert werden und benötigt dafür nur wenige Änderungen im Datenzugangscode.
Granulare semantische Deduplikation
Eine weitere Besonderheit sind die „Application Listeners“. Sie sind klein, stateless (speichern also keine Zustandsinformationen) und werden über ein Standard-API in die Datenbank integriert. Damit lassen sich Daten parallel auf einen zweiten Speicher streamen – ohne Unterbrechung (no choke point).
Dazu kreierten die CODR-Entwickler eine Scale-Out-Plattform, die die Datenbewegungen orchestriert, konsistente Backups veranlasst und Recovery-Operationen organisiert. Dieses Plattformprogramm liest die Daten, die die Applikation Listeners zum File oder Objekt im zweiten Speicher übertragen haben und bereitet sie für einen möglichen Recovery-Prozess auf.
Auch in puncto Deduplizierung haben sich die Entwickler etwas einfallen lassen: Statt blockbasierender wird jetzt die semantische Deduplizierung angewendet. Dabei werden nur die aktuellen Änderungen berücksichtigt, etwa ein einzelnes Element in einer einzigen Tafel. Daraus ergibt sich eine noch granularere Deduplikationsrate als bei herkömmlicher Vorgehensweise. Der Hersteller brüstet sich deshalb mit einer zehnmal so effizienten bidirektionalen Bewegungsrate im Vergleich zu anderen Methoden.

Neues in Version 2.5 von RecoverX
Kurz vor Weihnachten veröffentlichte die Company das Release 2.5 von Recover X. Damit lassen sich jetzt Recovery-Prozesse von Select-Abfragen starten, die spezifische Spalten oder Zeilen eines Backups betreffen. Damit wird das Recovery genauer und reduziert Zeit und Kapazität.
Sensible Spalten lassen sich zudem vom Recovery-Prozess ausschalten. Der Recovery-Prozess wurde zudem mit dem „inkrementellen Recovery“ ergänzt.
Er erlaubt die Wiederherstellung von Daten zwischen zwei Zeitpunkten statt wie bisher nur ab einem. Damit müssen nicht nur weniger Daten wiederhergestellt werden, sondern man kann daraus auch ein Archiv erstellen: Wiederhergestellte Daten lassen sich an einen Archivspeicher senden an den später nur mehr die geänderten Daten geschickt werden.
Für mehr Mobilität der Daten sorgt die neue Version 2.5 ebenfalls, denn Backup und Wiederherstellung können von überall aus gestartet werden. Zudem hat Datos IO bei Recover X 2.5 auch noch die Verschlüsselung, Autorisierung und Authentifizierung verbessert.
* Kriemhilde Klippstätter ist freie Autorin und Systemischer Coach (SE) in München.
(ID:45115063)
:quality(80)/p7i.vogel.de/wcms/da/40/da40af0217415826420831065d4b2714/0127889569v1.jpeg "„Klutch“ ist vendor- und cloud-agnostisch. (Bild: Anynines GmbH)")
:quality(80)/p7i.vogel.de/wcms/e8/67/e8673f6aedcb9eae0397f84647b727b2/0131657484v2.jpeg "Automatisierte Prozesse in Risikobewertung, Schadenbearbeitung und Kundenservice setzen leistungsfähige und souveräne KI-Infrastrukturen voraus.
(Bild: © Adobe Stock, Ekaterina Pereslavtseva)")