
:quality(80)/p7i.vogel.de/wcms/f3/a9/f3a9049aa1e439e65fe7180127740c95/0132375826v1.jpeg "Flexible Netzanschlüsse ergänzen den Netzausbau: Sie schaffen keine neue Stromerzeugung, können aber vorhandene Netzkapazitäten gezielter nutzen und so zusätzliche Rechenzentrumsleistung ermöglichen. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/3d/6c/3d6c66afae52794025baac731640ba82/0132384497v1.jpeg "Deutschland gilt für Unternehmen als bevorzugter Rechenzentrumsstandort. Für den weiteren Ausbau fehlen jedoch vielerorts passende Rahmenbedingungen. (Bild: Gemini / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/88/b8/88b82e63a564e2d174bc15891a5a7fb3/0132365761v1.jpeg "Adsorptionstechnologie macht Datacenter-Wärme zu Kälte. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/f0/00/f000f22eaa1c6ffff702b267b2ba525c/0132355546v1.jpeg "Modell eines 1-Megawatt-Mikroreaktors von Deployable Energy bis Containerformat (Bild: Depoyable Energy)")
:quality(80)/p7i.vogel.de/wcms/e1/a8/e1a8d01e55648bb2218a68d4132e3408/0132332613v1.jpeg "Suse und Openchip arbeiten daran, zum angepeilten Marktstart des Vektorbeschleunigers von Openchip einen passenden europäischen Softwarestack anzubieten. (Bild: Daniel Schrader / GPT Image 2 / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/0b/39/0b3998ee8075174ec8d14d166ff53bb3/0132267144v1.jpeg "Dell Technologies erweitert sein Portfolio für KI- und HPC-Infrastrukturen um eine Rack-Scale-Plattform mit hoher GPU-Dichte. (Bild: © Gorodenkoff - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/08/1a/081a7876f47ad1a1dbbaee94e9715a41/0132260078v1.jpeg "Warum KI-Agenten kein Selbstläufer sind: Agentische KI-Workflows stellen unterschiedliche Anforderungen an Rechenzentrums-Hardware. (Bild: © SVasco - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/22/d3/22d33c94c72328b03029e7d95765c0d9/0132298200v1.jpeg "Edge Computing verlagert Rechenleistung direkt an den Ort der Datenentstehung. Kubernetes entwickelt sich dabei zur gemeinsamen Plattform für KI-Anwendungen, Industrieprozesse und klassische IT. (Bild: © Annika - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/bb/84/bb848b79900a103b8aaed3207f1f1055/0132159005v1.jpeg "KI verändert die Wirtschaftlichkeit von Cloud-Infrastrukturen grundlegend. Wer Ressourcen weiterhin statisch bereitstellt, zahlt oft deutlich mehr als technisch erforderlich wäre. (Bild: © Zamrznuti tonovi - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/4d/ef/4def98d350a28359460e482100e1d3d8/0132138749v1.jpeg "V.l..: Georg Schmidt-Reindahl (Eplan), Marc Walter (Rittal), Uwe Scharf (Rittal), Tobias Funke (TOBOL), Cornelia Müller (Rittal) Steffen Schmidt (Rittal) und Philipp Müller (Rittal) (Bild: Rittal)")
:quality(80)/p7i.vogel.de/wcms/be/a9/bea9813088d28bae7b19799a194fe99c/0131951229v1.jpeg "Ewe hat seine Java-Umgebung über mehr als 100 Anwendungen und Zehntausende Desktop-Arbeitsplätze standardisiert. Nach Angaben des Unternehmens sanken dadurch die Java-Lizenzkosten um 60 Prozent. (Bild: © RomanR - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/1c/2e/1c2e0effc700eddefcf2264786aef800/0131879187v1.jpeg "Siemens erweitert sein Portfolio für industrielle KI bei der Verarbeitung von Produktionsdaten und bei der Automatisierung von Engineering-Prozessen. (Bild: Midjourney / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/74/74/7474bd5b4077a876d07eedacc3829cf1/0131673379v1.jpeg "Datacenter sind nicht nur eine Immobilie; sie sind heute Teil der Wärme- und Strom-Infrastruktur, sind als Daten- und Kommunikationsschlüssel systemrelevant und unterliegen damit den KRITIS-DACH- und NIS-2-Gesetzen sowie Reporting-Pflichten. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/99/2b/992bf8039e0c0a2818d7c01508cc2fd5/0132147095v1.jpeg "Stephan Reitzenstein vor der Probenkammer der Elektronenstrahl-Lithographie-Anlage: Diese Anlage stellt die hochpräzise Nanostrukturen für skalierbare Quantenlichtquellen her. (Bild: Felix Noak)")
:quality(80)/p7i.vogel.de/wcms/d0/75/d075ceeb4de4543fd6446dd4b26825d2/0131796600v2.jpeg "Am 21. Mai 2026 hat Globa lFoundries den Geschäftszweig „Quantum Technology Solutions“ ins Leben gerufen, der zur Skalierung der Fertigungskapazitäten gedacht ist. Der Geschäftsbereich startet mit Kundenverträgen und einer Pipeline von Quanteninnovatoren, die darauf ausgerichtet sind, auf seiner Plattform zu skalieren, so Silicon Saxony. (Bild: frei lizenziert: Gerhard Altmann)")
:quality(80)/p7i.vogel.de/wcms/01/1e/011eecedd1890f96971d8c6334e59403/0131873319v2.jpeg "Das Bild visualisiert einen Zufallszahlengenerator, der auf Quantenfluktuationen beruht (Bild: Fraunhofer IPMS/KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/6f/b7/6fb7ad8acdc584a2bfb3b9c28ae5cc29/0131860924v1.jpeg "Auf dem „Optica Quantum Summit 2.0“ stellt das Unternehmen in Glasgow vor, wie sie optische Übertragung in den Rechenprozess integrieren. (Bild: © Chanelle M/peopleimages.com - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/a9/a3/a9a38515d76d5d2bdbf552020689dd4c/0132133445v1.jpeg "Veraltete IT-Strukturen, steigende Sicherheitsanforderungen und moderne Workloads: Alles Gründe dafür, die Infrastruktur schrittweise zu modernisieren. Aber wie soll das gelingen, ohne den laufenden Betrieb zu gefährden? (Bild: © Chainarong - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/29/33/2933cd5e834f8070b6c6777334e0aa0e/0131690146v1.jpeg "Wie Unternehmen mit ausgealterten Daten und IT-Hardware ümgehen, ist auch und nicht zuletzt eine Frage der Sicherheit. (Bild: © VladaToday - stock.adobe.com / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/16/3c/163ca34e83af8b229e3babcdfbdfeeaf/0131682376v1.jpeg "Zu sehen ist das Äußere des Halbleiter-Leistungsschalters „Sentron 3QD2“. (Bild: Siemens)")
:quality(80)/p7i.vogel.de/wcms/84/22/8422b4b481480490a4a2001cb7a514d0/0132306234v1.jpeg "Die granulare Rollenkonfiguration in Kubermatic Virtualization 1.2 (Bild: Screenshot: Kubermatic // illustrativer Bildrahmen KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/25/ba/25ba46cb0d57f75776466da277dac3ff/0132182757v1.jpeg "Mit steigender GPU-Dichte wachsen auch die Anforderungen an die Leistungsfähigkeit und Skalierbarkeit der Storage-Infrastruktur. (Bild: © Gorodenkoff - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/b0/d2/b0d25dc406e49d03941be76e80573d67/0132410634v1.jpeg "Altman verspreche „das Blaue vom Himmel“, sagt ein hoher Beamter dem Handelsblatt. Was hinter den gescheiterten Verhandlungen zu einem deutschen OpenAI-Rechenzentrum steckt. (Bild: 577181671RR039_TechCrunch_D / TechCrunch / CC BY 2.0 / flickr.com)")
:quality(80)/p7i.vogel.de/wcms/0d/aa/0daafcf67c71b32b0ddb8a4ffc1fb3f5/0132391499v1.jpeg "M-net betreibt ein eigenes Glasfasernetz in Bayern und gehört mehrheitlich den Stadtwerken München. (Bild: © alphaspirit - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/f7/b6/f7b601cc2d73532d3cf1e28b2d3ef05d/0132349366v1.jpeg "Spanien gewinnt als Rechenzentrumsstandort weiter an Bedeutung. Projekte entstehen längst nicht mehr nur im Raum Madrid, sondern auch in weiteren Regionen des Landes. (Bild: © leonidkos - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/f3/da/f3dacd38e5834ae3f3c9d0a4bc9664d3/0113348475.jpeg "Das vom Umweltbundesamt beauftragte Projekt „Public Energy Efficiency Register of Data Centres “ (PeerDC), ist nach Einschätzung der Beteiligten Marina Köhn (UBA), Peter Radgen (IER Uni Stuttgart) und Felix Behrens (Öko-Institut e.V.) ein Erfolg auf ganzer Linie. Das sah DataCenter-Chefredakteurin Ulrike Ostler nach dem DataCenter-Diaries Podcast #16 nicht ganz so rosa. (Bild: sdecoret - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/90/f5/90f56ec6cb3ddbdabca2162fd5477836/0113078524.jpeg "(Bild: Vogel IT-Medien GmbH)")
:quality(80)/p7i.vogel.de/wcms/0f/09/0f097990002b7600075e43c92af4a3fd/0110524571.jpeg "(Bild: frei lizenziert/Krystsina Radzewich)")
:quality(80)/p7i.vogel.de/wcms/66/ae/66ae9e32738784b57e2ad8c1a4b0986f/0109756744.jpeg "Eines der in Deutschland befindlichen NTT-Datacenter - in Hattersheim - und das PeerDC-Logo. (Bild: NTT Global Data Centers )")
:quality(80)/p7i.vogel.de/wcms/ff/93/ff93dfcd6be86bedcea495f48574316b/0132223732v1.jpeg "Abwärme aus Bestandsrechenzentren? Ja, das geht, sagt Ralph Hintemann vom Borderstep Institut. (Bild: Midjourney / Paula Breukel / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/ad/1c/ad1ca8d7eab7d0c398db520687586a57/0132253970v1.jpeg "SNP, die schottische Regierungspartei, hatte sich noch Anfang 2026 gegen ein Datacenter-Moratorium ausgesprochen. Jetzt vollzieht sie eine Kehrtwende, sodass in Holyrood eine Mehrheit für ein temporäres Bauverbot möglich wird. (Bild: Yves Grandmontagne /DCmag)")
:quality(80)/p7i.vogel.de/wcms/ee/3f/ee3f063b82737f0369c09ba7854587b5/0127234708v1.jpeg "Das sind die Gewinner der IT-Awards 2025! (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/f1/f0/f1f007a4518fa65d3cb0ea5ca465142a/0121300054v3.jpeg "Strahlende Gesichter bei allen, die die Preise des 10. DataCenter-Insider Award am gestrigen 17. Oktober abholen durften - in den Kategorien: Schnelles Interconnect, Infrastruktur der Resilienz, Coole Kühlung, HPC- und KI-Hardware, Grünes Co-Location und Cloud-native Plattformen. (Bild: Manuel Emme Fotografie)")
:quality(80)/p7i.vogel.de/wcms/a8/28/a828f76369267628d833a12c26dd6579/0121131534v3.jpeg "DataCenter-Insider verleiht heute die IT-Awards 2024 in sechs Kategorien. (Bild: Vogel IT-Medien)")
Workshop I/O-Analyse am Beispiel SVC und Storwize V7000, Teil 2 Die Suche nach dem Verursacher der verlorenen Antwortzeit
Der Stau im Datenpfad ist nicht immer leicht zu finden. Mit dem Finden allein ist es jedoch nicht getan, da es danach um die bestmögliche Optimierung des Datenflusses geht. Die I/O-Analyse bietet häufig einige überraschende Optionen.
Anbieter zum Thema
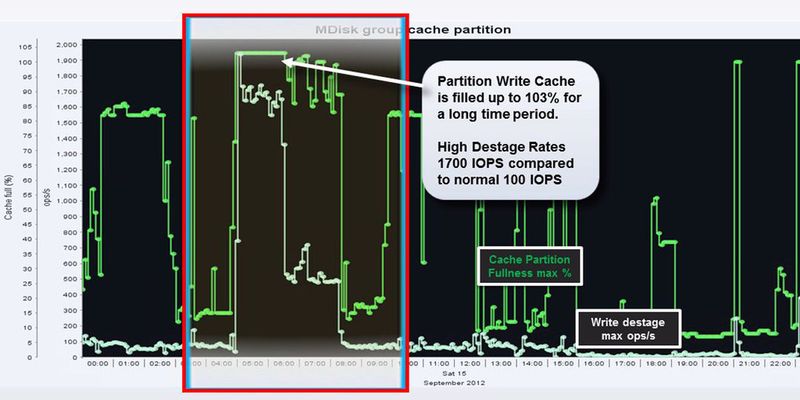
SVC segmentiert seinen Cache und teilt jedem Speicherpool (MDG) eine gewisse Menge Maximalcache zu. Der Vorteil aus dieser Segmentierung ist, dass die Pools untereinander abgeschottet sind.
Das hat zur Folge, dass die hohe Belastung der Cache-Ressourcen mit dem zugehörigen Speicherpool korreliert. Untersucht man den Cache des Speicherpools zum Zeitpunkt des Peaks, so findet man hier Auffälligkeiten, die deutlich auf Probleme hinweisen.
Die Suche nach den Volumes, die für die Überfüllung des Caches verantwortlich sind, gestaltet sich recht einfach. Man erzeugt eine Grafik mit allen Volumes aus dem Speicherpool und lässt sich deren Write-Datenraten anzeigen. (Abb. 7: Die Write-Datenraten aller Volumes)
In der Summe überlastet
Die zwei Volumes aus Abb. 7 werden in Abb. 8 detaillierter betrachtet. Wieder passt der Zeitraum der Schreiboperationen exakt zum Zeitraum, in dem die Probleme aufgezeichnet wurden und in dem der Partitions-Cache der Speicherpools überfüllt war. (Abb. 8: Limitierung der Volumes-Datenraten)
Bei genauerem Hinsehen stellt man fest, dass sich die beiden Volumes, die für die Überfüllung des Caches verantwortlich sind, in ihrer Ausführung gegenseitig behindert haben. Das zweite Volume (in rot), das anfangs mit 35 MByte/s startete, hat seine Performance auf 105 MByte/s erhöht, als das erste Volume mit seiner Arbeit fertig war.
- In Summe haben beide Volumes versucht, bis zu maximal 155 MByte/s Daten zu schreiben. Das war zu viel und hat zu einem Cache Overflow geführt.
- Als das erste Volume fertig war, hat das zweite Volume mit 105 bis 110 MByte/s weitergearbeitet, ein Datenvolumen, das der Backend-Speicher über einen längeren Zeitraum gerade noch aufnehmen konnte. Der Schreibcache wurde in diesem Zeitraum entlastet, aber - wie man in Abb. 3 sehen kann - sind die Antwortzeiten des Backend-Speichers nach wie vor sehr hoch. Das bedeutet, wir haben hier eine gute Einschätzung über die maximale Leistungsfähigkeit des Storage Backends gefunden.
- Wir erinnern uns: Die Probleme starteten um 5:00 Uhr und waren um 6:30 Uhr zu Ende. Von 5:00 bis 6:30 Uhr versuchten beide Volumes eine Datenrate von über 140 MByte/s zu erzeugen. Ab 6:30 Uhr war Volume 1 fertig und Volume 2 fuhr mit seiner Arbeit fort, die es mit bis zu 105 MByte/s beendete. Ab 6:30 Uhr gab es keine Probleme mehr im Speicherpool. Offensichtlich sind die 105 MByte/s für den Pool und das dahinter liegende Speichersystem kein Problem, 140 MByte/s und mehr jedoch schon.
Beide Volumes gehören zu einem Server und wahrscheinlich gehören beide Volumes auch zu einem Backup-Prozess. Wenn man die Ausführung der beiden Schreibprozesse hintereinander schalten könnte, würde sich die gesamte Laufzeit beider Schreibprozesse nur um 30 Minuten verlängern. Durch diese „schonende“ Art des Schreibens würden in diesem Zeitraum keine Latenzprobleme für die anderen Volumes auftreten.
(ID:36553230)
:quality(80)/p7i.vogel.de/wcms/b6/b8/b6b861346b607b7ecc0b60dc45c46012/0129449658v1.jpeg "IBM stattet seine FlashSystem-Modelle 5600, 7600 und 9600 mit KI-Agenten aus. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/01/57/0157bd3a882ee5b00df773dc6ad30d64/0130317537v1.jpeg "Kioxia zufolge liefert die „GP“-Serie hohe Leistung und geringe Latenz für die Speichererweiterung der „Storage-Next“-Architektur von Nvidia. (Bild: Kioxia)")